MS&E435系列⑦:AI 真正昂貴的不是訓練,是每一次回答背後的推論成本
如果把這一波 AI 浪潮只看成模型競賽,很容易看錯重點。
原始影片:Stanford MS&E435 Economics of the AI Supercycle | Spring 2026 | Inference
逐字稿與畫面
Stanford MS&E435 Economics of the AI Supercycle | Spring 2026 | Inference · 49 個片段
如果把這一波 AI 浪潮只看成模型競賽,很容易看錯重點。
模型當然重要。誰有更強的前沿模型,誰就能定義能力上限。可是當 AI 開始進入每一個產品、每一個工作流程、每一次使用者互動時,真正每天被刷出來的帳單,不是訓練,而是推論。
訓練像蓋工廠。推論像工廠每天開機生產。
前者轟動,後者持續吃掉毛利。
Baseten 創辦人兼 CEO Tuhin Srivastava 在 Stanford MS&E435 的這堂課裡,把這件事講得很直接:推論需求不是成長一千倍,也不是一百萬倍,而可能是十億倍。
這句話聽起來誇張,但它背後不是科幻口號,而是一個商業判斷:AI 如果真的成為應用層的基本能力,使用量會跟著每一次搜尋、每一段語音、每一份病歷、每一次程式碼補全、每一個 agent 任務一起增加。
也就是說,推論會變成 AI-first economy 的銷貨成本。
這個判斷對創業者和企業都很殘酷。過去大家比較關心「我能不能把模型接進產品」,現在問題變成「我能不能在使用量放大後還賺錢」。只要產品成功,token 就會變多;只要使用者留存變好,成本也會跟著上升。
對很多應用公司來說,AI 成本不再是早期實驗費用,而是產品本身的核心成本線。
這也是為什麼推論基礎設施會從背景服務,變成戰略問題。
Baseten 看到的是應用層的毛利戰
Baseten 的位置很有意思。
它不是前沿模型公司,也不是單純出租 GPU 的雲端供應商,而是站在應用公司和算力市場中間,替客製模型、後訓練模型與生產環境推論處理效能、可靠性、多雲調度與開發者體驗。
Tuhin 提到的客戶名單,包括 Abridge、Cursor、Notion、Superhuman、World Labs 等,代表的是同一類壓力:這些公司不是「想玩 AI」,而是已經把 AI 放進核心產品。
以 Whisperflow 為例,它做的是語音到文字、語音到鍵盤的體驗。表面上看起來是一個輸入工具,背後卻不是單一模型能解決的問題。它可能同時需要音訊模型、語言模型、延遲控制、串接與穩定服務,任何一步慢了,使用者就會感覺卡頓。
Abridge 則更極端。它面向醫療場景,要把診間或手術室裡發生的內容轉成臨床紀錄,還要深度整合醫療系統。這種產品不只需要準,還需要可靠、可監控、可合規,因為停機或錯誤不是小瑕疵。
這就是 Baseten 主張的市場空間:應用公司真正需要的不是裸算力,而是一條可以把模型穩定送進生產環境的路。
裸 GPU 就像買到一塊地,還不等於有工廠。雲端帳號裡有 H100 或 B200,也不等於可以穩定地服務數百萬使用者。
應用公司會先去找 AWS、GCP、Azure 或各種 AI cloud,然後很快發現,站在 compute 上面還有一整層推論堆疊要自己搭:runtime、batching、路由、可觀測性、版本管理、故障切換、資安與客戶支援。
Tuhin 把這件事拆成幾個核心能力:效能、可靠性、多雲與開發者平台。效能決定單次請求的延遲與成本;可靠性決定服務能不能跨雲端、跨叢集持續運轉;多雲能力決定公司能不能在算力緊缺時找到替代來源;開發者平台則決定團隊能不能在不犧牲安全與監控的情況下快速部署。
這些能力加起來,才是應用層公司願意付溢價的理由。
推論會成為 2030 年前最大的 AI 市場
課堂裡最重要的一張判斷,是「推論會成為 2030 年最大的市場」。
投影片把推論定義為 AI-first economy 的 COGS,也就是交付 AI 價值時必然發生的成本。這個說法的力量在於,它不把推論看成工程細節,而是看成商業模型的底層變數。
當 AI 滲透到工作和生活的每一面,推論支出就會至少跟使用量線性成長。使用越多,成本越高。

投影片裡列出幾個數字:AI 支出整體以每年 50% 到 100% 的速度成長;Gartner 預估 2027 年 AI 支出會到 3.3 兆美元,其中推論支出約 1.3 兆美元,並在 2030 年超過 3 兆美元;NVIDIA 也預期 2027 年晶片銷售可達 1 兆美元,而需求主要由推論帶動。
這些數字不必被當成精準預言,但它們描繪了一個方向:推論不是模型發布後的附屬環節,而是 AI 商業化後最大、最持續、最難被忽略的支出項目。
這對創業者的啟示很實際。若一家公司靠 frontier API 快速做出產品,初期可能是正確選擇,因為速度比效率重要。但一旦產品找到市場,成本結構就會反過來逼迫它重新設計模型策略。
每一個 token 都是毛利的一部分。每一次請求都會進入損益表。當使用量成長十倍、百倍,原本看似可以接受的 API 成本,就可能變成公司無法上市、無法融資、甚至無法活下去的原因。
更麻煩的是,推論成本不是只靠議價就能解決。
它牽涉模型大小、工作負載形態、延遲要求、上下文長度、cache、batching、硬體供給、地域分布與客戶 SLA。
也因此,真正成熟的 AI 應用公司會同時思考兩個問題:第一,哪些任務必須使用最強的 frontier model;第二,哪些任務可以改用後訓練或開源模型,以更低成本提供足夠好的體驗。
這不是信仰問題,而是產品毛利問題。
後訓練模型的理由:不是反 frontier,而是要活下來
Apoorv 問了一個很尖銳的問題:如果開源模型或後訓練模型只是落後 frontier 模型幾週或幾個月,企業何必費力分支出自己的模型?
萬一下一代 GPT 或 Claude 直接超越你剛調好的模型,不就白忙一場?
Tuhin 的回答分成兩層:一個務實理由,一個更防禦性的理由。
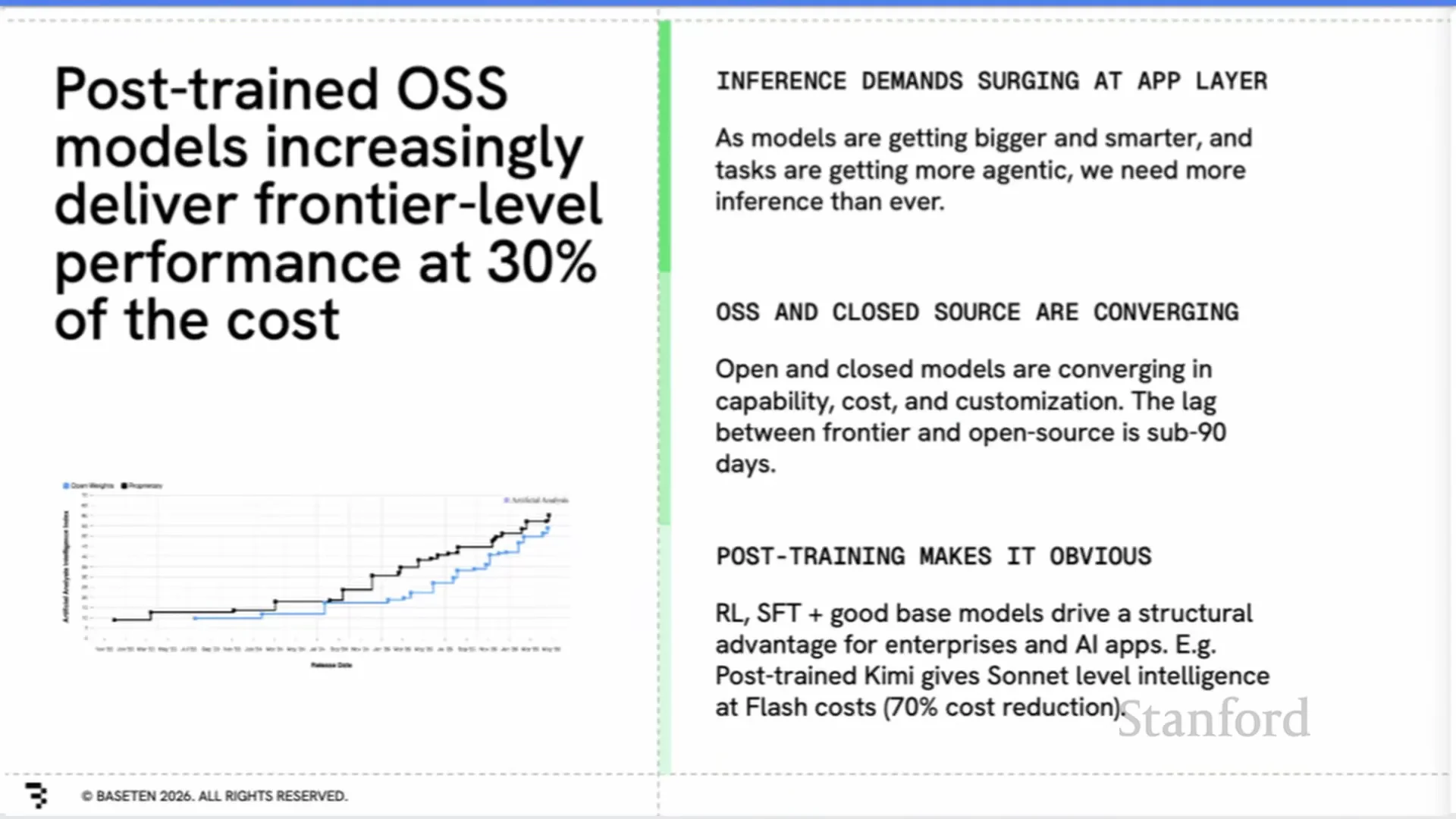
務實理由是成本。Tuhin 認為,開源模型大約落後封閉模型 90 天,但運行成本可以便宜 70% 到 90%。
這個落差一旦進入高用量產品,就不是小優化,而是公司能不能把 gross margin 從零拉到 40%、50%、60%、70% 的問題。對已經有產品市場契合的公司而言,模型能力只要夠好,成本差異就會變成生死線。
尤其是 coding、醫療紀錄、語音輸入、客服 agent 這些高頻應用,token 成本會非常快地放大。
防禦性理由則更敏感。
Tuhin 的觀點是,應用公司的護城河往往不是模型本身,而是 workflow、使用者訊號、專有資料與產品脈絡。如果所有智慧都透過 frontier lab 的 API 交付,應用公司也等於把最珍貴的使用資料和工作流程訊號交給上游。
短期看,這很方便;長期看,上游模型公司可能學到足夠多,反過來切入你的產品。
這就是他用「East India Company」比喻的原因:合作可能同時也是權力轉移。
所以,後訓練不是為了在每一個 benchmark 上贏過 frontier model,而是為了把一部分智慧的控制權拿回來。企業可以選一個夠好的 base model,把自己的資料、偏好、獎勵函數、工作流程拿來做 SFT 或 RL,讓模型在特定任務上更便宜、更穩定、更貼近產品目標。
這個策略不是萬能,但它提供了一條路:不要把所有核心價值都寄託在別人的模型 API 上。
這裡的關鍵是「足夠好」的定義會被產品場景改寫。
醫療紀錄需要的是可靠、可追溯、符合法規;語音輸入需要的是低延遲與語境理解;程式碼工具需要的是能在特定 repo、特定風格、特定開發流程裡提高成功率。
當任務變窄,客製化就有機會打敗通用能力。
後訓練模型的優勢,不是抽象智慧更高,而是在特定產品裡,成本、速度、可靠性與資料控制權的組合更好。
Baseten 平台其實在賣一個推論作業系統
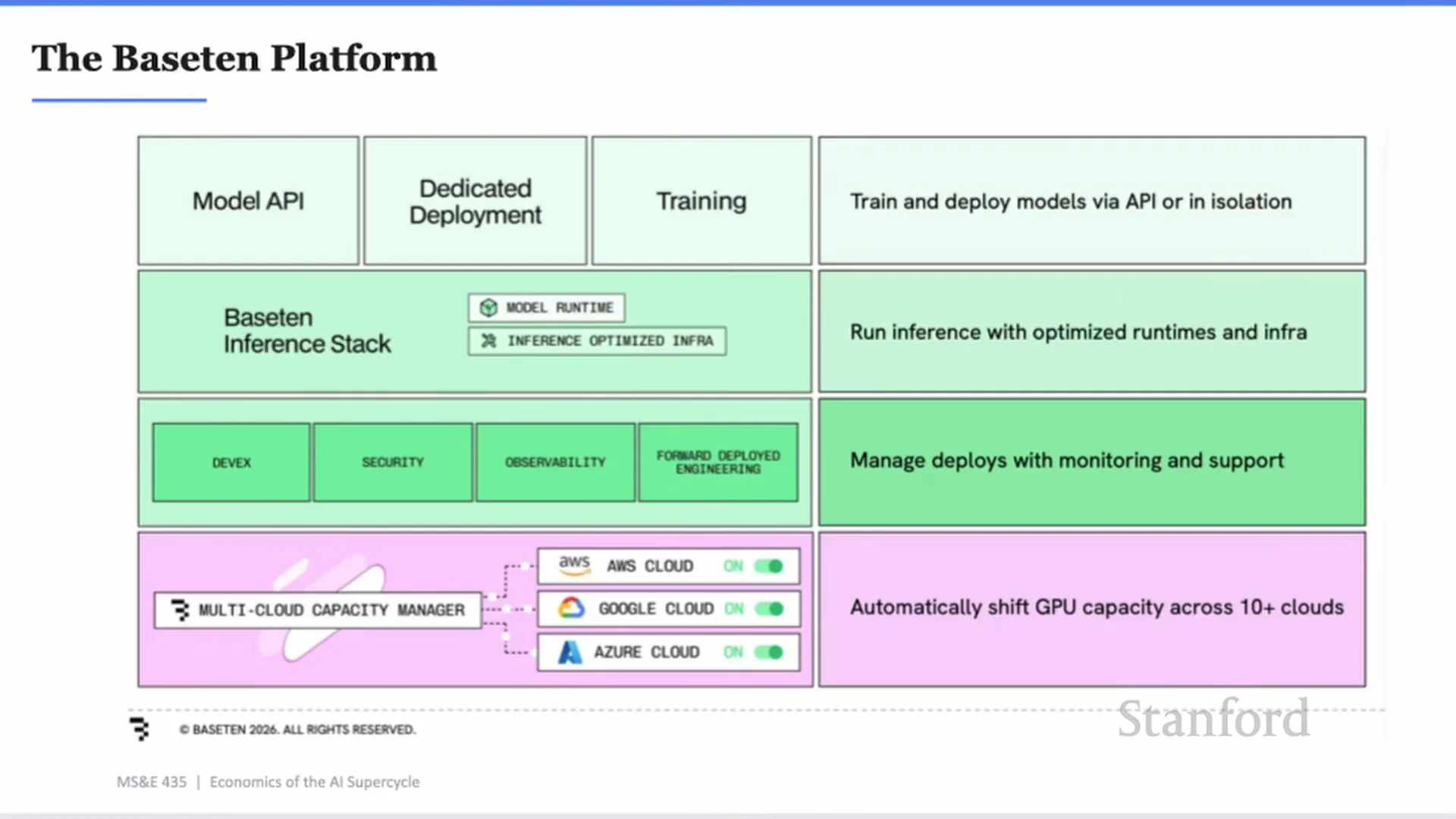
Baseten 平台投影片看起來像產品架構圖,但它揭示的是另一件事:推論市場不會只是一個模型 endpoint 市場。
上層是 Model API、Dedicated Deployment、Training;中間是 inference stack、model runtime、inference optimized infra;旁邊是 DevEx、Security、Observability、Forward Deployed Engineering;底層則是跨 AWS、Google Cloud、Azure 等多雲容量調度。
這不是單點工具,而是一個把模型送進生產環境的作業系統。
為什麼這層會有價值?
因為應用公司不想把每一個底層問題都重做一次。當模型越來越多,工作負載越來越複雜,團隊需要的不只是「部署成功」,而是能在產品成長時持續部署、監控、升級、轉移與擴容。
模型 runtime 要跟硬體能力貼合;infra 要能處理高峰與故障;DevEx 要讓工程師不必為每次部署重新摸索;security 和 observability 則是企業客戶願意買單的基本門檻。
這也解釋了為什麼 Baseten 現在主要靠 compute markup 賺錢。
客戶買到的不是比較便宜的原始 GPU,而是包了軟體能力的 compute。Tuhin 也承認,Baseten 的 H100 或 B200 會比 raw compute 更貴;問題是,客戶願不願意為整個軟體堆疊付溢價。
當推論是產品核心服務時,停機、延遲或錯誤路由的代價可能遠高於單小時 GPU 價格。對成熟應用來說,最便宜的 compute 不一定是最低風險的選擇。
未來定價也可能從 GPU-hour 走向 token。
這代表 Baseten 這類平台會越來越接近應用公司的成本結構:客戶不只關心用了幾張卡,而是每一百萬 token、每一次任務、每一個產品 outcome 到底花多少錢。
當後訓練工作流程被納入平台,推論平台就不只是「跑模型」,而是從資料、效用函數、base model、後訓練、部署到監控的一整個閉環。
開源模型是美國 AI 生態的必要條件
課堂中段有一段討論轉向開源模型。
Tuhin 的立場不是浪漫式的開源信仰,而是生態安全與市場結構的考量。他認為,好用的開源模型必須存在;如果十年後世界上沒有好的開源模型,那對美國會是很糟的事。
原因很簡單:如果智慧成本在某些地方便宜 70% 或 90%,而其他地方只能依賴少數昂貴封閉模型,應用層創新就會被成本結構限制。
這裡有兩個風險。
第一是過度集中。若世界只剩少數 frontier lab 掌握最強模型,應用公司、企業與開發者就會被迫接受它們的價格、產品路線與資料政策。
第二是地緣競爭。Tuhin 提到,許多強開源模型來自中國團隊。這件事本身不代表它們不好,反而顯示中國團隊非常強;但美國也需要自己的高品質開源模型,否則應用層公司會在成本與可控性上失去選擇。
他也提到,美國大型公司其實可能比外界想像中更投入開源,只是成果還沒有完全浮現。NVIDIA、Microsoft、Google 等公司都有動機支持某種形式的開源或開放生態,因為它們不一定都想讓智慧被兩家公司完全壟斷。
這個判斷重要之處在於,開源不是單純免費模型,而是一種市場平衡力量。它讓應用公司有能力後訓練、有能力持有自己的智慧、有能力把成本壓到可持續範圍。
對企業來說,這不是要在「封閉」和「開源」之間做宗教選擇,而是要設計 portfolio。
高風險、高難度、需要最強推理的任務可以用 frontier model;高頻、可定義、資料充足、成本敏感的任務,則應該評估開源或後訓練模型。
成熟的 AI 架構不會只有一個模型,而會像現代資料系統一樣,由多個模型、多種成本層級、多個部署策略共同構成。
算力短缺不會自然消失
如果前半場談的是模型與應用,後半場真正的重點是供給。
Tuhin 說 Baseten 目前跑在 18 個雲端之上,甚至可能已經是 20 個,並把 87 個不同叢集縫合在一起。
這些數字透露一個現實:算力不是一個乾淨、透明、成熟的市場。它更像早期商品市場,有資訊不對稱、有關係網、有臨時調度、有價格劇烈變動,也有供應商突然改價的風險。
他提到一個很有畫面感的例子:某個 B200 合約原本價格已經很高,續約時對方在 5 月就提出下一年度價格翻倍。
這不是傳統雲端服務那種穩定降價曲線,而是高需求、低供給、強議價權交織出的市場。
當 Baseten 這種平台本身服務的 token 量已經非常大,它需要的不是「多買一點卡」,而是要在兩年內規劃到 150,000 個 B200 equivalent 的等級。
Tuhin 估算,這可能意味著 70 億美元級別的 compute spend。
這也解釋了為什麼他不認為 compute scarcity 會回到正常。
若推論需求真的以巨大倍數增加,供給即使快速擴張,也可能永遠追不上新需求。
就像機場安檢,清晨 5 點沒有人排隊,不代表機場沒有容量問題;到了早上 8 點,人龍就會出現。而 AI 推論更麻煩,因為全球需求沒有真正的午夜。
美國低峰時,歐洲或亞洲可能上升;某個產品降溫,另一個 agent 工作流可能又開始吃掉更多 token。
因此,推論公司真正的三大風險不是單一工程問題,而是結構性問題:開源模型是否足夠好、應用層是否能獨立存在、平台是否拿得到足夠 compute。
前兩者關乎模型與產品,第三者則關乎硬體、資本、能源、供應鏈與資料中心建設。
這也是為什麼 Tuhin 後來談到,如果他沒有在做 Baseten,他會對能源、電力、資料中心空間與模組化資料中心感興趣。
下一個創業題目可能不是模型,而是標準化 compute
談到下一個創業點子時,Tuhin 的答案很具體:模組化資料中心。
他從貨櫃的歷史類比出發。貨櫃之所以重要,是因為它標準化了貿易的單位,讓全球物流可以被工業化、規模化、流程化。
那麼,在 AI 時代,誰能標準化 compute unit,誰就可能讓算力部署進入真正的工業化階段。
今天的資料中心建設仍然高度非標準。
不同地方的電力條件不同,冷卻方式不同,機櫃密度不同,網路不同,維修流程不同,財務結構也不同。當每一個案場都像客製工程,供給就很難快速擴張。
若能把資料中心或 compute module 變成更一致的單位,後續就可能出現一整個服務產業:標準維護、標準部署、標準融資、標準遷移,甚至形成某種 compute API。
這個想法對創業者有一個重要提醒:AI 基礎設施的機會不只在模型層,也不只在應用層。
當推論需求爆炸,瓶頸會一路往下傳導到晶片、電力、建築、散熱、資本市場和供應鏈。模型越聰明,任務越 agentic,後端所需的物理世界就越龐大。
AI 看似是軟體浪潮,但它最後會重新塑造硬體與能源經濟。
這也讓「學什麼才安全」這個問題變得不那麼直覺。
Tuhin 給學生的建議是,不必把自己鎖在單一熱門技能裡,因為職涯會變,人在六個月內也可能深入一個新領域。
真正值得追的是你願意深挖、且會與這波結構性變化相交的問題。
有人會做模型,有人會做應用,有人會做資料中心融資,有人會做能源,有人會做 runtime。
AI 超級循環不是單一賽道,而是一整個經濟系統。
誰掌握推論,誰掌握 AI 的損益表
這場課最值得帶走的,不是 Baseten 本身,而是一個判斷框架:AI 的上半場看模型能力,下半場看推論經濟。
能力決定產品能不能出現,推論成本決定產品能不能長大。
當每家公司都能呼叫強模型,差異會慢慢轉向誰能用更低成本、更高可靠性、更強資料控制權,把智慧嵌入自己的工作流程。
對企業來說,接下來的 AI 策略不能只問「用哪個模型」。
更好的問題是:哪些任務值得付 frontier premium?哪些任務可以被後訓練模型接手?我們的使用者訊號是否正在變成別人的資料資產?推論成本在產品成功後會不會摧毀毛利?我們是否有跨雲、跨模型、跨硬體的彈性?
這些問題聽起來不如模型發布會刺激,卻更接近公司最後會不會賺錢。
對創業者來說,這也是一張地圖。
推論平台、模型 runtime、多雲 capacity manager、後訓練工作流、可觀測性、資安、B200 供給、資料中心標準化、能源與融資,都可能是 AI 超級循環裡的關鍵位置。
真正的大市場通常不在最閃亮的展示層,而在每一次使用都必須付費、每一次成長都會放大的成本層。
推論就是這一層。
如果 Tuhin 的判斷成立,AI 未來最大的問題不是「模型會不會更聰明」,而是「我們能不能負擔這些聰明」。
誰能讓推論更便宜、更穩、更可控,誰就不只是賣工具,而是在改寫 AI 應用公司的損益表。
這也是為什麼推論不是配角。它可能是 AI 商業化真正的主戰場。
【資料來源】
- MS&E 435 | Economics of the AI Supercycle - Stanford 課程頁,說明課程定位與 Tuhin Srivastava 的講者角色。
- Stanford MS&E435 Economics of the AI Supercycle | Spring 2026 | Inference - Stanford Online。用途:本篇課堂主素材。
- Baseten - Baseten 官方網站。用途:Baseten 對 production inference、open-source/custom models 與高效能 model serving 的定位。
- The Baseten Inference Stack - Baseten。用途:Inference Runtime、Inference-optimized Infrastructure 與平台堆疊說明。
- How Baseten achieves 225% better cost-performance for AI inference - Google Cloud。用途:Baseten 在 Google Cloud 與 NVIDIA GPU 上做 production-grade inference 的公開案例。
- Baseten | NVIDIA Customer Stories - NVIDIA。用途:Baseten 使用 Blackwell 平衡推論成本、延遲與模型能力的案例。
- Gartner Says Worldwide AI Spending Will Total $2.5 Trillion in 2026 - Gartner,2026-01-15。用途:AI 支出與基礎設施投資背景。
- Baseten CEO and co-founder Tuhin Srivastava on the AI inference cloud - No Priors。用途:Tuhin 對 inference demand、application layer、post-training 與 specialized models 的延伸訪談背景。
本頁由影片逐字稿、截圖與 AI 整理生成,內容可能需要回到原始來源查證。