MS&E435系列⑥:通用模型只是地板:企業 AI 真正難的是「學會你的公司」
很多人以為 AI 的競賽,就是下一個模型比上一個模型更聰明。
原始影片:Stanford MS&E435 Economics of the AI Supercycle | Spring 2026 | Enterprise Internal Knowledge
逐字稿與畫面
Stanford MS&E435 Economics of the AI Supercycle | Spring 2026 | Enterprise Internal Knowledge · 54 個片段
很多人以為 AI 的競賽,就是下一個模型比上一個模型更聰明。
參數更多,資料更多,算力更多,榜單分數更高。然後某一天,模型足夠強,一切企業流程就會自動被吃掉。
Yash Patil 在 Stanford MS&E435 的這堂課裡,給了一個更冷靜的答案。
通用模型會繼續變強。這點沒錯。但企業真正要的不是一個「什麼都懂一點」的天才。企業要的是一個知道公司內部資料、懂工作流程、遵守偏好、能被評測、能從回饋改善的專用系統。
翻譯成白話:未來企業 AI 的勝負,不是誰把 ChatGPT 接進 Slack。是誰能把自己公司的隱性知識,變成模型可學、可查、可評估、可持續改善的系統。
這也是 Yash 創辦 Applied Compute 的核心理由。他曾在 OpenAI post-training 團隊工作,參與 evals、reasoning models,以及後來走向 Codex 的 agentic coding 研究。離開 OpenAI 後,他和共同創辦人 Rhythm Garg、Linden Li 轉向一個更企業化的問題:如果模型已經夠聰明,為什麼它進公司後還是常常不知道該怎麼做?
答案不是「再等下一代模型」而已。
答案是:你的公司沒有把「好工作」定義成模型可以最佳化的東西。
深度學習的第一個奇蹟,是我們不用再手刻規則
Yash 從 AlexNet 開始講模型史。這不是懷舊,而是在說 AI 進步一直是「瓶頸轉移」。
在 AlexNet 之前,很多機器學習工作仰賴手工特徵。人類要先告訴系統什麼是邊緣、角落、紋理,再讓分類器判斷圖像裡是不是一隻貓。這是一種兩段式工作:人先設計特徵,模型再用特徵做判斷。
AlexNet 之後,深度學習改變了這件事。模型可以直接從資料中學表徵。你給它大量圖像、標籤和 GPU,它自己學出有用的中間表示。這是現代 AI 的第一個大轉折:人類不必再把每個規則寫死。
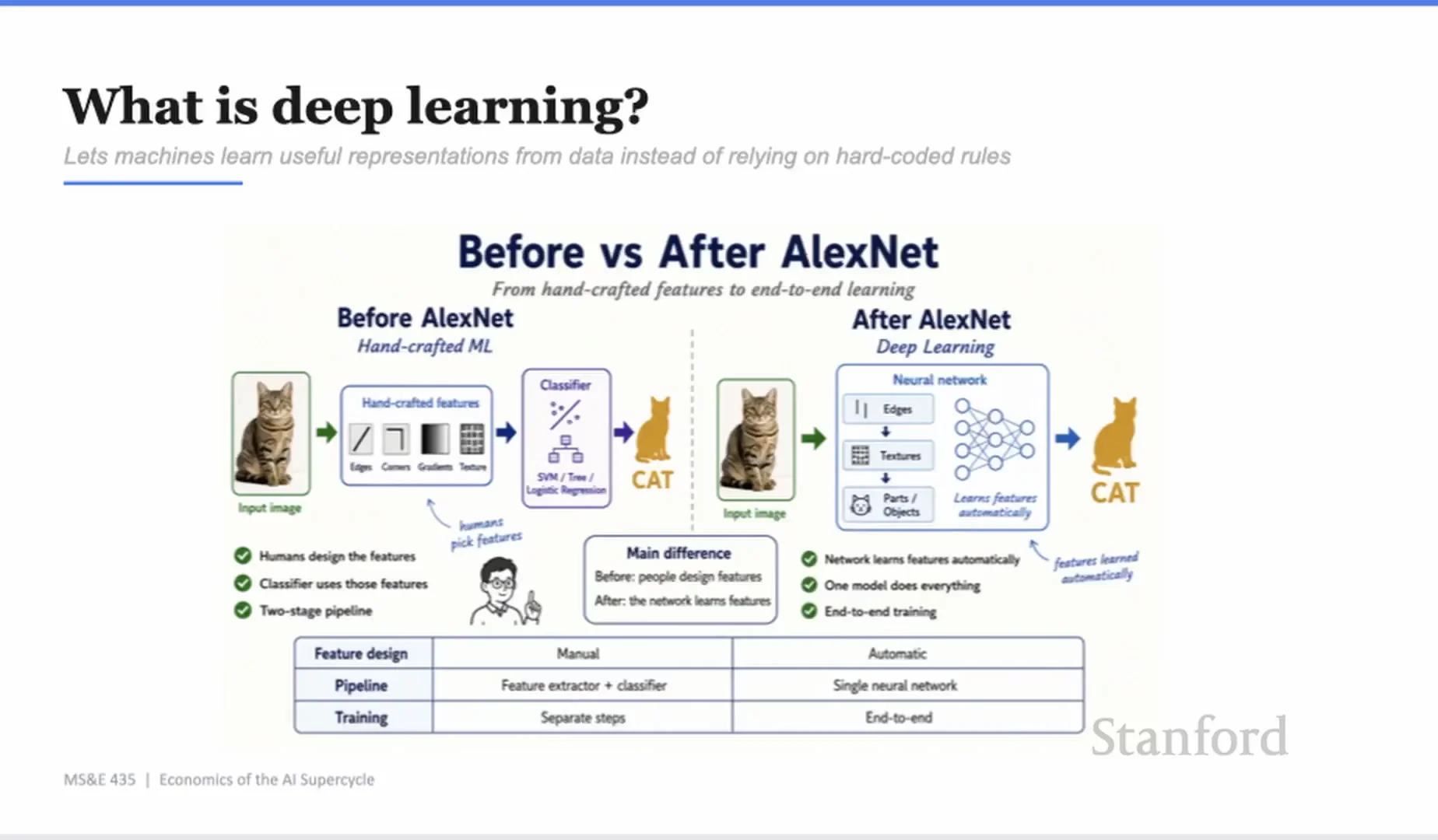
但代價也出現了。
Yash 說,這也是我們開始不真正理解模型在做什麼的時刻。它很會預測,很會分類,很會從資料中學模式,但它的內部表示不是人類手寫的規則表。模型變強,透明度反而下降。
這個張力一路延續到今天。大型語言模型(Large Language Model)本質上仍是在做下一個 token 的預測。只是當資料、模型、架構和算力一起放大,這個看似簡單的目標,開始長出某種通用能力。
Transformer 之後,模型進步變成一條規模化路線
Yash 接著把時間拉到 2017 年。Transformer 和 self-attention 的出現,讓語言模型訓練更容易擴展。相較於 RNN 或 LSTM,注意力機制讓模型更有效處理長序列,也更適合在 GPU 上跑大規模訓練。
接著是 2018 到 2019 年的 pre-training 時代。研究者把大量文本丟進模型,讓它預測下一個 token,用 cross-entropy loss 調整權重。這聽起來像單純壓縮文字,但規模拉大之後,模型開始學到語言、知識、推理模式、世界結構。
OpenAI scaling laws 和 GPT-3 證明,模型變大、資料變多、算力變多,能力會跟著提升。Chinchilla scaling laws 又補上一層:不是只把模型做大就好,資料量也要跟上,才是 compute-optimal。
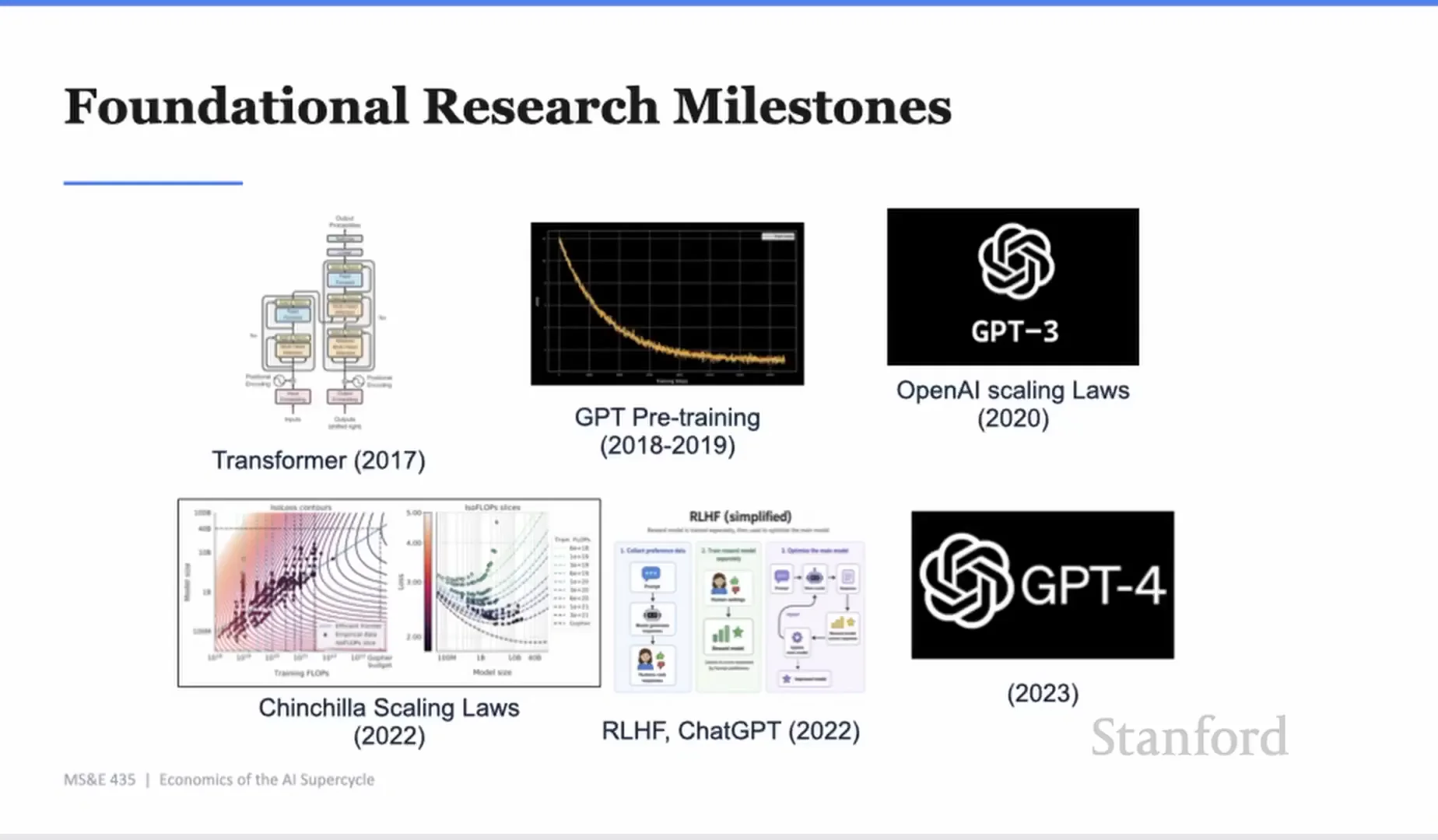
這段歷史的重點,不是每篇論文的年份。重點是 AI 的瓶頸一直在移動。
早期瓶頸是手工特徵。後來是資料和 GPU。再來是序列架構。接著是足夠大的 pre-training。ChatGPT 之後,瓶頸變成可用性與對齊,也就是模型不只要會接下一個 token,還要知道使用者真的要什麼、什麼不能回答、什麼回答才有幫助。
到了 2024 之後,瓶頸又移到 reasoning、RL environments、evals 和 verifiable rewards。

這就是 Yash 的核心脈絡:AI 不是一條直線升級,而是一連串瓶頸被拆掉後,新的瓶頸浮上來。
o1 之後,推理變成新的 scaling axis
Yash 對 reasoning models 的描述很有意思。他說,o1 這類模型代表一個新的智慧擴展軸線:test-time compute。
以前我們比較熟悉的是 train-time compute。你花更多算力訓練模型,模型變強。reasoning model 則多了一個維度:回答問題時,模型願意花更多時間思考、修正、推演,表現也會變好。
OpenAI 在 o1 的公開說明裡也提到,模型表現會隨著更多 reinforcement learning 和更多 test-time compute 改善。這和 Yash 在課堂上的說法一致:chain-of-thought reasoning 不是工程師手寫出來的規則,而是在受限環境與大量算力下長出的能力。
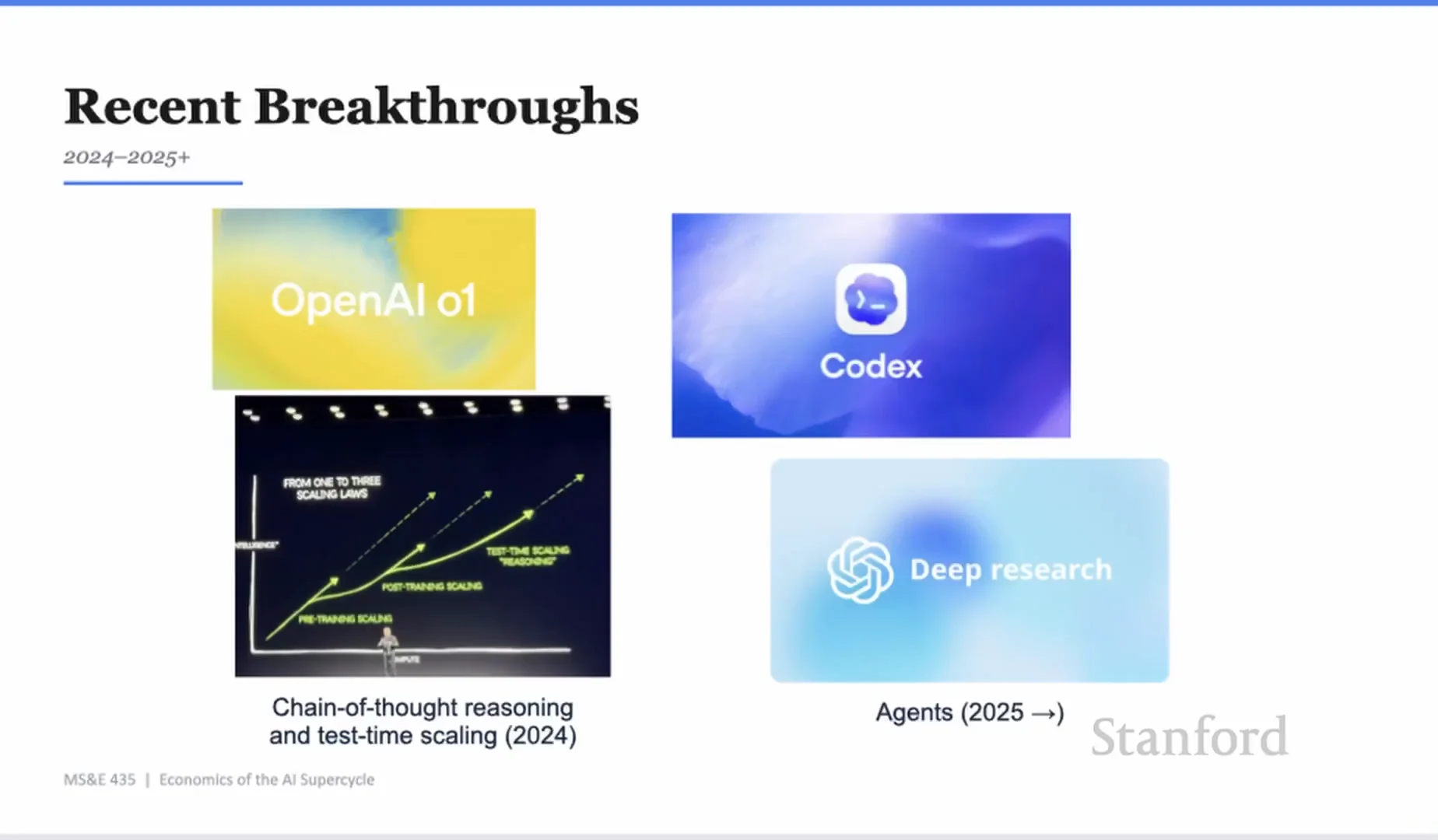
再往前一步,reasoning 結合 tool use,就變成 agents。Codex、Deep Research 這類系統不是只回一句話。它們能做長時間任務,能查資料、寫程式、跑測試、修正結果。這也是為什麼 Yash 說,今天大家開始把它們稱為 AI coworkers。
但 coworker 這個詞有一個陷阱。
真正的同事不是只會推理。真正的同事知道公司怎麼做事、誰有決策權、什麼格式可以交、什麼標準算好、什麼錯誤不能犯。通用 reasoning 只是第一步。進入企業後,模型還要學會組織脈絡。
為什麼所有實驗室先攻程式碼?
Apoorv 問了一個很關鍵的問題:為什麼幾乎所有 AI labs 都把軟體工程當成第一個 frontier?為什麼不是財務、簡報、客服、法律、生命科學?
Yash 的答案是:程式碼有可驗證獎勵。
如果模型寫了一段程式,你可以編譯它。可以跑 unit tests。可以檢查功能是否符合需求。這讓 code 和 math 成為 reinforcement learning with verifiable rewards 特別適合的領域。
AI 要從行動中學習,就需要 reward signal。很多工作很難定義 reward。簡報好不好,策略好不好,法律備忘錄完整不完整,常常不是一個單元測試就能判斷。但程式碼有比較明確的驗證器。錯就是錯,過就是過,至少比大多數知識工作清楚。
第二個原因是資料。網路上有大量 code tokens,也很容易產生 synthetic tasks。你可以建立一個程式環境,要求模型實作功能,讓它嘗試幾百次或幾千次,再用測試結果當獎勵分布。這不是單純讀程式碼庫,而是在一個可互動環境裡學會做事。
第三個原因更激進:很多研究者認為 coding models 某種程度上是 AGI-complete。因為許多任務拆到最後,都可以表達成程式碼、工具呼叫或自動化流程。模型寫程式,不只是為了幫工程師省時間,而是用 code 作為和真實世界互動的通用語言。
這就是為什麼 Codex 不是單純的「自動補程式碼」。OpenAI 的企業材料也把 Codex 定位成能使用開發工具、在受控環境運作、處理複雜任務的 agentic coding 系統。它代表的是一種更廣義的工作模式:模型不只回答,模型開始操作。
Pre-training 是壓縮,post-training 是讓模型變成可用員工
Yash 對 pre-training 和 post-training 的區分很清楚。
Pre-training 是壓縮。你拿網際網路規模的資料、數兆 token、龐大 GPU 叢集,透過 transformer 訓練一個模型去學語言模式。最後得到一組權重,裡面壓縮了大量人類知識與模式。
但 base model 不等於好助理。它只是很會預測下一段文字。
如果你問「我該邀請誰吃晚餐?」base model 可能直接吐一串名字。可是合理的助理應該說:我不知道你認識誰,你可以先告訴我邀請名單嗎?如果使用者問危險問題,模型也不能只是延續文字模式,而要知道安全邊界。
Post-training 做的就是這件事。它把原始能力轉成有用行為。方法包含 supervised fine-tuning、preference tuning、RLHF、RLVR、安全訓練、eval-driven iteration。資料不再只是網頁文字,而是人類示範、偏好排序、專家標註、合成任務、RL environments。
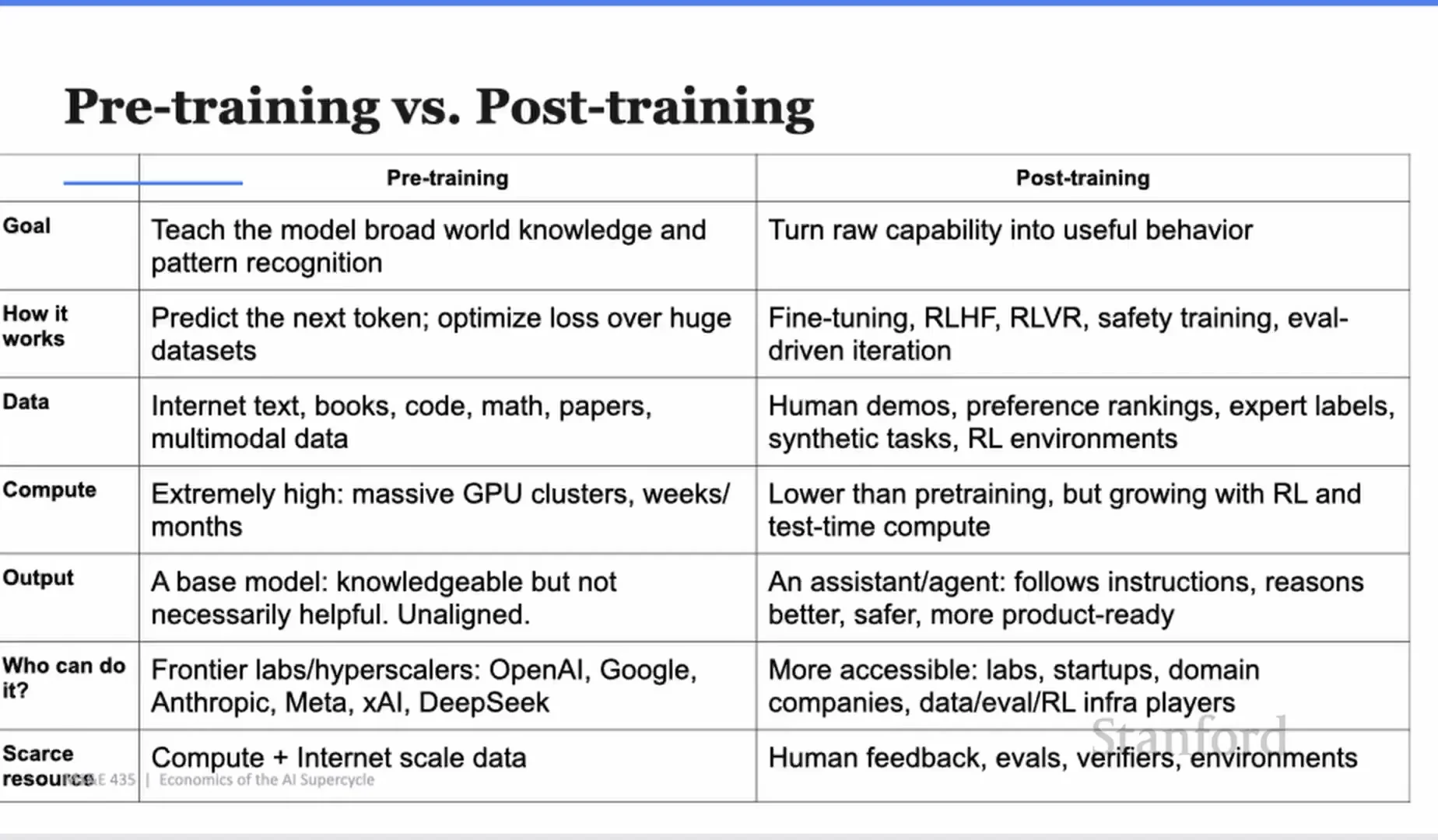
這裡的經濟學很重要。
Pre-training 需要 massive capex,只有 frontier labs 和 hyperscalers 能玩。Post-training 的門檻低很多,雖然隨著 RL 和 test-time compute 發展,算力需求也在上升,但企業仍然可以用比 pre-training 少得多的投入,讓模型對特定任務表現更好。
這就是 Applied Compute 的切入點。不是每家公司都要重訓一個基礎模型。它們真正需要的是把既有模型變成懂自己業務的模型。
Evals 不是考試,是企業的路線圖
Yash 曾在 OpenAI 做 evals。他說這是沒人想碰、但很重要的工作。
原因很簡單:evals 定義你要爬哪座山。
如果你想訓練好的 code model,就要先定義什麼叫「好的程式碼工作」。SWE-bench 之所以重要,是因為它讓大家有一個共同目標,可以開始最佳化。但任何 eval 都有缺陷。它會塑造模型行為,也會製造 train/test mismatch 的風險。
這對企業尤其重要。
J.P. Morgan 和 Goldman Sachs 對「好答案」的定義不會完全一樣。DoorDash 對菜單結構的判斷,也不會等於 Uber Eats 或某家餐飲 ERP 的標準。每家公司都有自己的流程、格式、風險偏好、審核標準。
所以企業如果沒有自己的 evals,就等於沒有自己的 AI 路線圖。

這也是通用模型的限制。通用模型設定地板。它可以讓每個人都站到一個不錯的起點。但企業要拉高天花板,就要把自己的「好」和「壞」編碼進模型可學習的系統裡。
DoorDash 案例:提示工程不夠,因為你要最佳化的是結果
Yash 用 DoorDash merchant onboarding 舉例。
DoorDash 每年有超過十萬家商家上線。商家會提供各種非結構化資料,尤其是菜單。把一張菜單圖片變成 DoorDash 店面,看起來像資訊擷取問題,但實際上很難。因為 DoorDash 有自己的 style guide:哪些選項是 modifier,哪些是 add-on,哪些可以混搭,哪些是特殊配料,品項應該怎麼掛在一起。
通用模型看得懂菜單,卻不一定懂 DoorDash 的菜單規則。
Yash 說,他們試過 prompting,但真正有效的是直接最佳化目標。先讓模型輸出,讓人類修正菜單,理解差異,再把模型輸出和 ground truth 對照,量化錯誤率,最後針對降低錯誤率訓練。
結果是課堂資料提到的 30% relative reduction in critical menu errors。
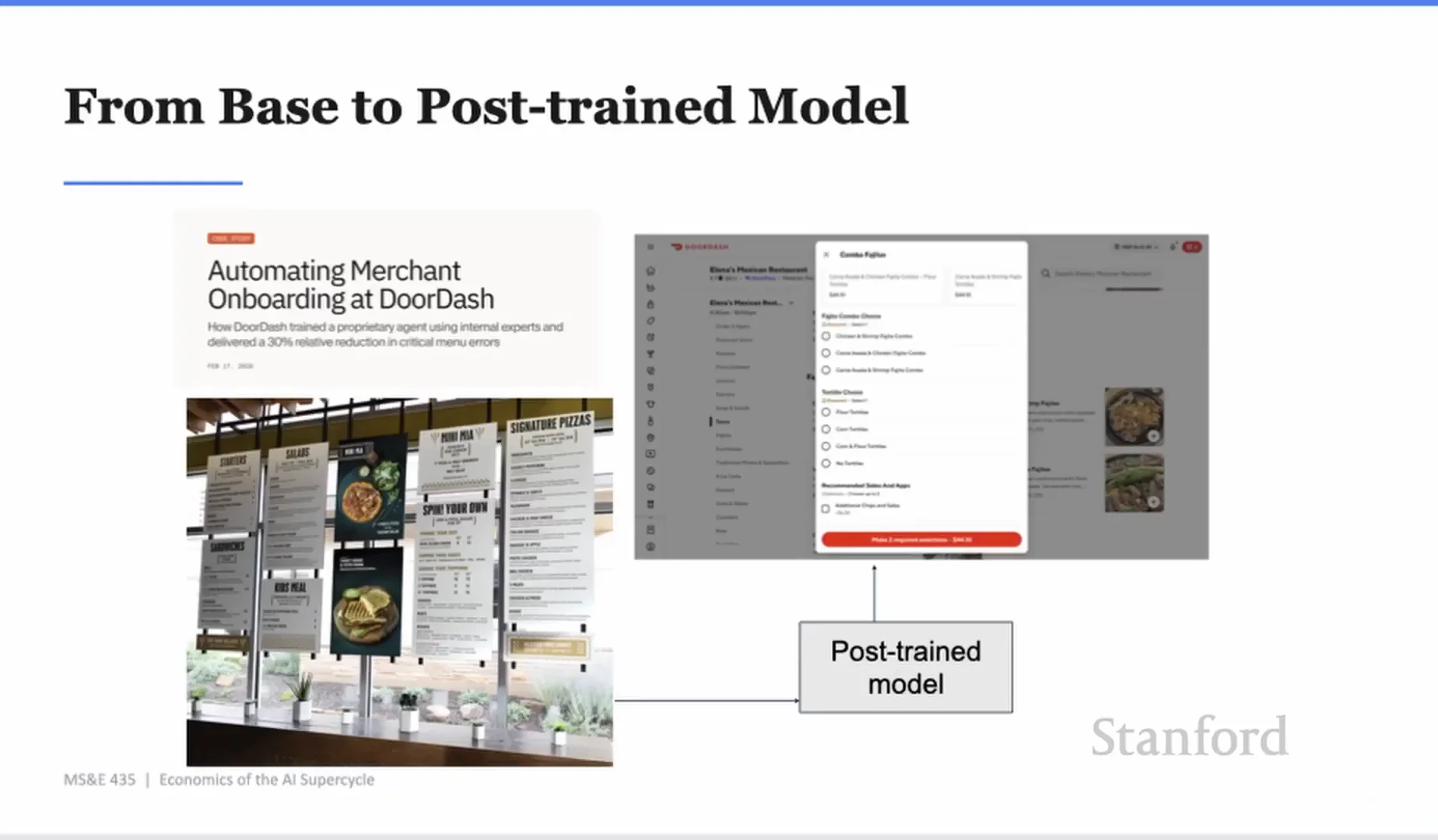
這個案例的重點不是餐飲外送。重點是:企業 AI 的核心,不是把文字丟給模型叫它「請更準」。核心是把業務標準變成 reward、loss、eval、training data。
只要企業能清楚定義什麼是好結果,就可以直接朝結果最佳化。這比無止境調 prompt 更接近工程,也更接近可複製的競爭力。
等下一代模型,還是現在開始專用化?
Apoorv 問了一個很多企業都會問的問題:如果未來 GPT-17 開箱即用就更好,為什麼現在要特化模型?
Yash 的回答是,企業在意的是任何時間點都在 frontier。
世界是碎片化的。資料分散在不同公司、不同工具、不同文件、不同流程裡。就算通用模型變強,它也不會自動知道你公司的所有專有資料、工作偏好與操作細節。更重要的是,企業要的是 time to value 和 ROI,不是等待一個抽象的 AGI。
Post-training 的吸引力就在這裡:用少一個數量級的 compute,把模型調到你的任務上。不是替代 frontier model,而是在 frontier model 之上建立公司自己的專用層。
Applied Compute 公開資料把這稱為 Specific Intelligence。它存在兩個地方:一個是模型權重,另一個是 agent runtime 時能取得的 context。前者透過 targeted RL、專家資料和任務環境改善模型;後者透過 context engine 把公司任務、偏好、流程和過去 agent traces 整理成可檢索的 contextbase。
這個設計有一個實用含義:有些智慧不需要每次都重新推理。可以被記住、整理、取回,分攤到後續每次 agent rollout 裡。Applied Compute 的研究說,context 可以降低 reasoning effort,在部分 benchmark 上改善表現,也能讓 agent 從「太貴不能每張票都跑」變成「成本足夠低,可以全面部署」。
Continual learning 不會突然降臨,它會先從資料權限開始
Yash 認為未來瓶頸是 continual learning。也就是模型能不能從真實世界互動裡,用極少回饋學會改善。
人類碰到熱爐子一次,就學會不要再碰。今天的模型還不行。它們需要大量例子、可重放環境、明確獎勵、平行 rollout。真實企業環境更難,因為 reward 稀疏、結果延遲、使用者行為很吵,而且資料權限複雜。
所以 continual learning 不是按一個開關。它會是漸進式 rollout。
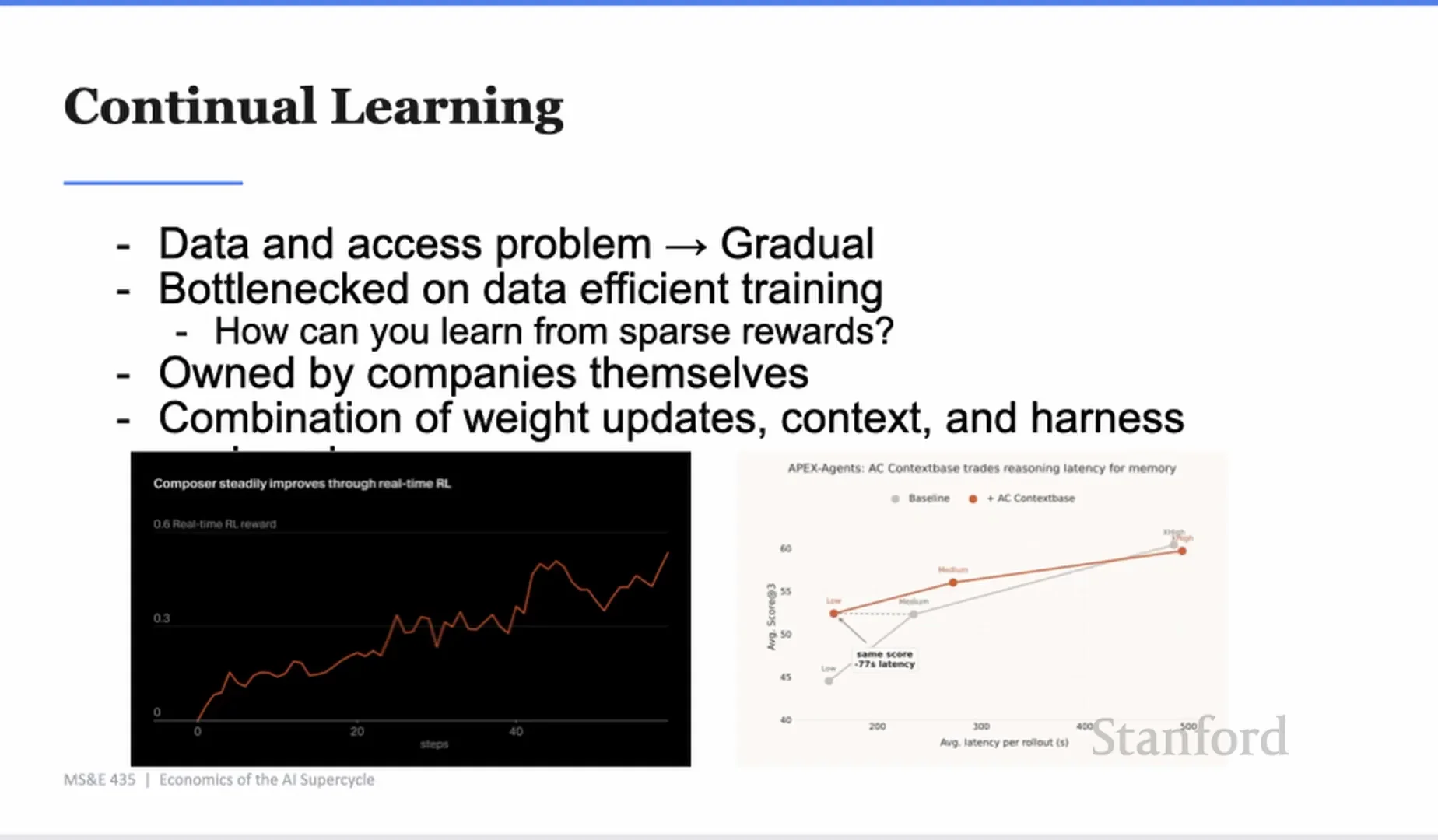
Yash 舉 Cursor Composer 為例。它可以收集使用者是否接受建議、是否 revert、是否保留程式碼,然後把這些當成 implicit rewards,進行線上訓練。這不是離線 RL 那種可重播、可平行跑幾千次的乾淨環境。它更接近真實產品:動態、吵雜、不完整,但也更有價值。
企業場景也會走這條路。哪些客服回覆被主管改掉?哪些財務分析被採用?哪些法律草稿被合夥人重寫?哪些程式碼被保留?哪些 agent 行動造成下游錯誤?
這些都是 feedback,但它們不會自動變成訓練資料。公司需要權限、紀錄、標準、evals、資料治理和系統設計,才能把它們變成模型可學習的訊號。
所以 Yash 說,continual learning 本質上是 data access problem。
Transformer 可能不完美,但現在押注替代架構還太早
課堂後段談到 non-transformer models。很多人批評 transformer 不夠有效率、耗電、需要大量資料。這些批評不一定錯。
但 Yash 的立場很務實:scaling transformers works。
只要這條路還能繼續變聰明,最有資源的 labs 就會繼續投資。不是因為 transformer 是物理定律,而是因為整個基礎設施已經圍繞它長出來。資料中心、GPU、軟體堆疊、研究方法、訓練流程、人才經驗,都在支援這條路。
反方也有道理。人類不需要讀完整個網路才能學語言,所以理論上應該存在更資料有效率的架構。也有人直接在晶片層最佳化新架構。但在看到真正的牆之前,主流資本仍會押在能確定產出能力的路線。
這裡的判斷很像上一場 Sachin 談基礎設施:理想架構和可部署架構,不是同一件事。
在 AI supercycle 裡,能不能 work 不夠。還要能 scale、能供應、能被工程團隊操作、能被產品吸收、能被企業採用。
下一個機會:不是資料市場消失,而是資料形態改變
最後的 long-short 問題裡,Yash 看好 compute 和 NVIDIA 這類晶片供應商。他提到 NVIDIA 晶片有很高的利潤率,labs 花數千億美元在 compute 上,未來有動機自己做 chip design,讓模型訓練、架構和晶片更緊密共同設計。
這個判斷和 #05 的 infrastructure 主題互相呼應。模型層的進步,最後還是會回到硬體、能源、晶片效率與供應鏈。
但更有趣的是他對 data market 的保留。
他不是說資料會死。相反地,他說資料市場每隔幾年就被說要死,但一直沒有死。只是它會變。
原因是 RL task 有一個弔詭:你幫客戶把模型訓練得更強,也讓下一輪任務更難。模型愈聰明,簡單標註愈沒有價值;下一波資料必須更難、更貼近真實環境、更能提供 verifiable reward。
在程式碼裡,unit tests 可以驗證結果,不一定需要人類逐題判斷。模型愈強,synthetic data 的生成流程也會愈強。那資料公司的價值,就不再只是雇人標答案,而是設計下一代環境、任務、驗證器與專業回饋。
Yash 提到下一波可能是 robotics data、egocentric data。也就是戴上 GoPro,收集第一人稱視角的真實世界資料。這說明資料市場不是結束,而是從「文字標註」走向「環境建構」。
企業 AI 的三個問題
這堂課最值得帶走的,不是某個 benchmark,也不是某個 startup 名字。
是企業 AI 的判斷框架。
第一,通用模型只能設定地板。它讓你不用從零開始,但不會自動給你公司級差異化。天花板來自專有資料、工作流程、evals、reward definitions 和可持續改善的系統。
第二,post-training 的價值在於把能力轉成行為。企業不用自己 pre-train 一個基礎模型,但需要知道什麼是好輸出、誰能修正錯誤、哪些回饋可以被模型學到。
第三,agent 的競爭不是單一模型競爭,而是模型、context、harness、工具、資料權限、使用者回饋的組合競爭。很多應用層公司真正的創新,不是在 prompt,而是在這個 harness。
所以問題不是「AI 會不會取代企業工作」這麼粗。
真正的問題是:你的企業有沒有能力把自己的工作,變成 AI 可以學習與改善的環境?
如果沒有,模型再強,也只是外面來的聰明陌生人。
如果有,AI 就不只是工具。它會慢慢變成公司內部知識的一種新載體。
這才是 Applied Compute 這類公司的賭注。
通用智慧會繼續往前跑。但企業價值,往往藏在通用模型看不到的地方:你的資料、你的流程、你的判斷標準、你的錯誤修正紀錄,以及你每天怎麼把工作做對。
【資料來源】
- MS&E 435 | Economics of the AI Supercycle - Stanford 課程頁,說明課程定位與 Yash Patil 的講者角色。
- Ex-OpenAI Staffers Raise $20M For New Startup Applied Compute - Upstarts,2025-06-27。用途:Applied Compute 創辦與募資背景。
- Introducing Applied Compute - Linden Li / Applied Compute。用途:Specific Intelligence、創辦人背景與公司定位。
- Remember, Refine, Retrieve: A Context Engine for Enterprise Agents - Applied Compute。用途:Context Engine、contextbase、APEX-Agents / GDPVal 表現與企業 agents 架構。
- Attention Is All You Need - Vaswani et al., 2017。用途:Transformer 與 attention 架構背景。
- Learning to reason with LLMs - OpenAI,2024-09-12。用途:o1、reinforcement learning、test-time compute 與 reasoning scaling。
- OpenAI named a Leader in enterprise coding agents by Gartner - OpenAI,2026。用途:Codex 作為企業 coding agent 的定位。
- APEX Benchmarks: The AI Productivity Index - Mercor。用途:長週期、跨應用專業 agent 任務 benchmark 背景。
- Scaling Data leads to SOTA Legal Performance on APEX-Agents - Mercor。用途:Applied Compute post-trained model 在專業任務上的表現與工具使用分析。
本頁由影片逐字稿、截圖與 AI 整理生成,內容可能需要回到原始來源查證。