MS&E435系列⑤:AI 的下一個瓶頸,不是模型,是「把電送到 GPU」
如果你只看產品介面,AI 像是一個軟體故事。
原始影片:Stanford MS&E435 Economics of the AI Supercycle | Spring 2026 | Infrastructure, Capstone Case
逐字稿與畫面
Stanford MS&E435 Economics of the AI Supercycle | Spring 2026 | Infrastructure, Capstone Case · 35 個片段
如果你只看產品介面,AI 像是一個軟體故事。
打開 ChatGPT,輸入問題,等幾秒,答案出現。打開 Codex,丟一個任務,它讀程式碼、改檔案、跑測試。這看起來像模型能力的進步,也像軟體體驗的進步。
但 Sachin Katti 在 Stanford MS&E435 的這堂課裡,幾乎把這個直覺翻掉。
他談的不是「下一個模型多聰明」。他談的是一個更硬、更重、更接近工業現場的問題:你要怎麼把足夠多的晶片、記憶體、網路、冷卻、電力、土地、建築和工程人力,在同一個時間點湊齊,讓一個吉瓦級的 AI 系統真的上線。
翻譯成白話:AI 產業現在不只是在訓練模型。它正在重建一套新的工業基礎設施。
這也是為什麼 Sachin 的背景特別有意思。他曾是 Intel 的 CTO 與 AI 主管,後來加入 OpenAI,負責 industrial compute。Apoorv Agrawal 介紹他時說,Sachin 幾乎看過從電子、底層基礎設施、一路到 agent 的完整鏈條。這不是客套話。這場對談的重點就在這裡:當 AI 從聊天機器人走向代理型工作,真正的競爭會從「誰有模型」變成「誰能把智慧交付到全世界」。
營收是落後指標,算力才是前導指標
Apoorv 一開始問了一個很投資人的問題:OpenAI 的運算能力和營收,看起來高度相關。這件事要怎麼理解?
Sachin 的回答很直接。對 frontier lab 來說,營收基本上是落後指標。真正的前導指標,是你有多少可用算力,以及這些算力用得多好。
這句話很值得停一下。
傳統軟體公司的核心約束,通常是產品、銷售、留存、毛利率。伺服器成本當然重要,但不是最根本的生產限制。AI 不一樣。當模型能力夠強、使用者需求夠大、任務愈來愈複雜,公司的收入上限很大一部分會被「能提供多少 token」決定。
Sachin 說,過去三年 OpenAI 的算力每年大約翻三倍,營收也跟著翻三倍。他不認為這種關係已經到盡頭。因為使用者不只是拿 AI 來聊天,還開始拿它做一般知識工作、寫程式、分析資料、執行長時間任務。任務愈複雜,消耗的 token 愈多,背後需要的推論運算也愈多。
這也是 OpenAI 對「30 吉瓦」這種數字有興趣的原因。Sachin 把它描述成一個遠大的目標,分配給研究與產品。研究端需要更多算力去探索新模型、新方法、新智慧邊界;產品端需要更多算力把智慧交付給使用者,而不是用各種限制把需求壓下來。
這裡的關鍵不是「OpenAI 想蓋很大的資料中心」而已。
關鍵是商業模式變了。當 AI 產品的使用量、智慧程度、使用者願意付費的價值,都和可用算力綁在一起,算力就不再只是成本科目。它是收入的先行產能。
推論不是產品尾端,它正在變成主戰場
很多人談 AI 算力,直覺會想到訓練。也就是花一大筆錢,把大型基礎模型訓練出來。
Sachin 的觀點不同。他認為 scaling laws 已經從 pre-training 擴展到整個運算生命週期。這裡面包含 post-training、強化學習、合成資料、產品使用,以及 agent 執行任務時的一連串推論。
換句話說,推論(inference)不只是模型上線後的服務成本。它正在變成研究方法、產品體驗和下一代模型訓練的一部分。
他提到一個很重要的比例:未來可能 80% 以上的運算都會是推論。這不是因為大家突然只做聊天產品,而是因為許多看起來像「訓練」的事情,其實也在消耗推論。例如用模型產生合成資料,再拿來訓練新模型;用強化學習讓模型在環境裡反覆嘗試;用 reasoning model 在回答前花更多時間思考。這些都不是傳統那種一次性 pre-training。
外部研究也在往同一個方向走。NVIDIA 將 scaling laws 拆成 pretraining、post-training 與 test-time scaling,並指出 reasoning model 會在推論時間投入更多運算。關於 inference scaling laws 的研究也顯示,增加推論時的搜尋、投票、樹狀探索等策略,有時比單純放大模型更能改善問題解決表現。
這帶出一個反直覺結論:AI 的「使用」本身,正在變成 AI 的生產過程。
使用者問問題、模型思考、工具呼叫、測試、回饋、再嘗試。這些表面上是產品互動,實際上也是運算被消耗、資料被生成、模型能力被推進的地方。
所以當推論變成主戰場,基礎設施的設計也會變。你不能只問「哪張 GPU 訓練最快」。你還要問:哪種硬體適合低延遲?哪種記憶體架構適合長上下文?哪種系統能支撐 agent 反覆呼叫工具?哪種網路能讓數十萬顆晶片穩定協作?
一個吉瓦不是數字,是五十萬顆 GPU 的協調問題
Apoorv 問 Sachin:你的工作最難的是什麼?是拿到算力嗎?是電力嗎?是能源嗎?是晶片嗎?是土地嗎?
Sachin 的答案是:全部都是。
他說,當你談 AI compute,不能只想到 GPU。你必須同時想到晶片、記憶體、網路、電力、冷卻、資料中心建築、發電、配電、土地。這些全部加起來,才叫 compute。
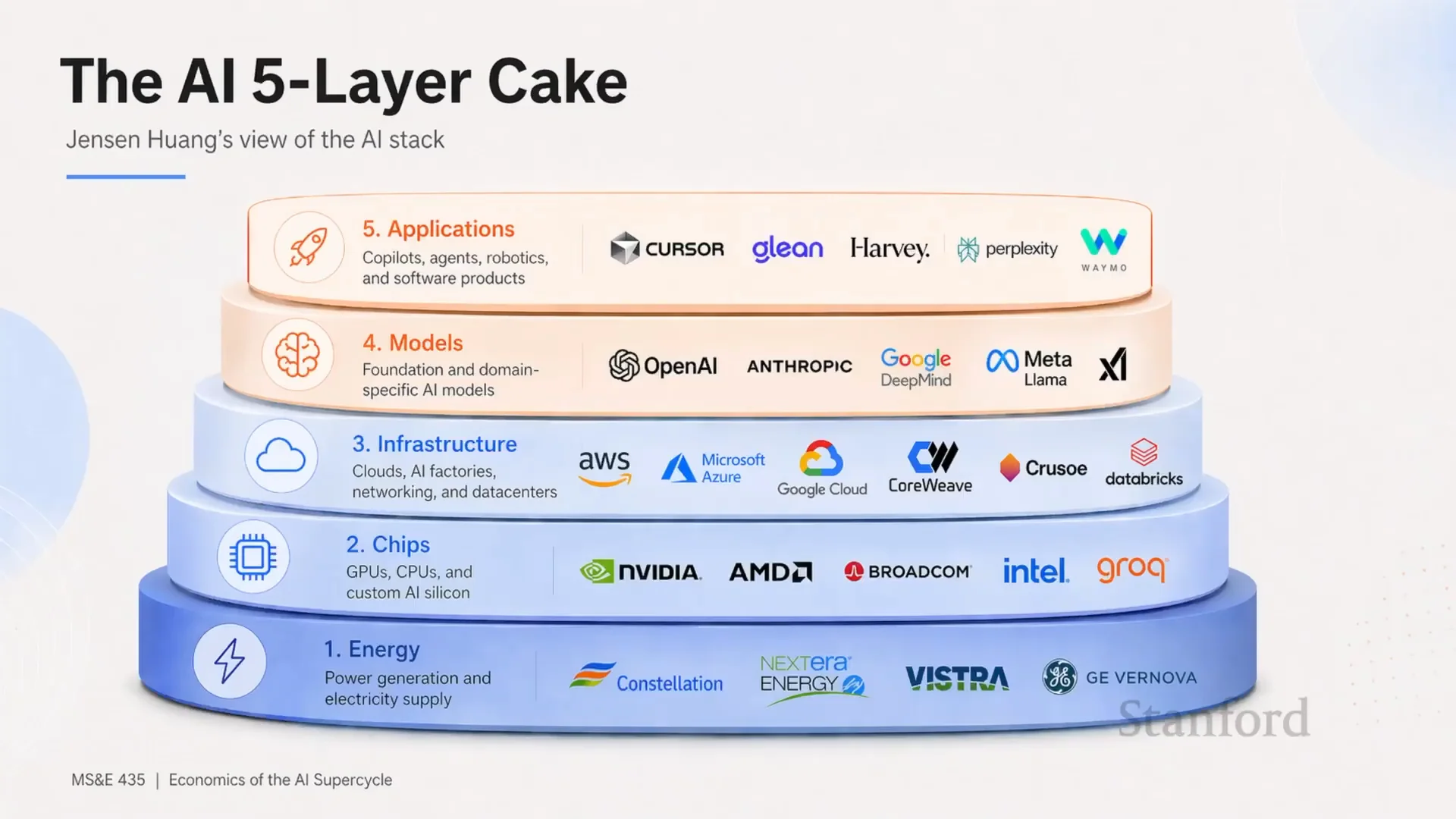
這句話幾乎是整場課的核心。
軟體人習慣把 compute 想成 API 背後的抽象資源。雲端時代把伺服器變成按鈕,把資料中心變成彈性容量。但 frontier AI 的規模太大,抽象層開始失效。當你要的是一吉瓦、十吉瓦、三十吉瓦,問題不再是「多開幾台機器」。問題是整條供應鏈要同時到位。
Sachin 給了一個尺度:一吉瓦大約等於五十萬顆 GPU。十吉瓦就是好幾百萬顆晶片,要被連在一起、供電、冷卻、維持穩定,還要確保它們以足夠高的效能跑起來。
更麻煩的是,簽約只是開始。
他說,有趣的部分是簽合約,困難的部分是簽完之後。供應商真的能交貨嗎?不同零組件能同時抵達嗎?系統工程能不能讓這些晶片在這個規模下協同運作?電力和冷卻波動會不會讓晶片降頻?整套系統上線後能不能被實際使用,而不是只存在於簡報或採購合約裡?
這讓 AI 基礎設施更像建機場、蓋電廠、造半導體廠,而不是傳統 SaaS 擴容。
OpenAI 公開的 Stargate 計畫也反映這個方向。官方資料提到,Stargate 需要雲端、資料中心、晶片、能源、建設、金融與營運夥伴共同參與。OpenAI 與 Oracle 的 4.5 吉瓦合作,加上 Abilene 等基地,已經把規模推到數百萬顆晶片等級。這些公開數字和 Sachin 課堂上的描述互相呼應:AI 現在是 gigawatt-scale 的工程問題。
資料中心正在變成電網裡的新物種
一個吉瓦級資料中心放到喬治亞或密西根,會發生什麼事?
Sachin 的回答不是「電費變高」這麼簡單。他說,大型訓練工作負載通常是同步的,強度會一起上升、一起下降。這代表電網可能在短時間內看到數百兆瓦的負載波動。而現有電網不是為這種行為設計的。
換句話說,AI 資料中心不是一般商辦,也不是普通工廠。它是會快速變動、集中消耗、對電力品質敏感的新型負載。
這也是為什麼他提到,OpenAI 需要思考如何避免對其他基礎設施造成附帶傷害。要降低供應鏈風險,也要思考晶圓廠、記憶體工廠、天然氣、核能、配電系統的長期配置。
外部能源資料可以補上更大的背景。IEA 估計,2024 年全球資料中心用電約 415 TWh,約占全球用電 1.5%;到 2030 年,Base Case 可能接近 945 TWh,接近翻倍。IEA 也指出,2025 年資料中心用電增加 17%,AI-focused data centers 成長更快,同時變壓器、燃氣渦輪、先進晶片、電網審批都出現瓶頸。
在美國,EPRI 的估計更尖銳:資料中心到 2030 年可能消耗 9% 到 17% 的美國發電量。部分州的占比會更高,像維吉尼亞本來就是資料中心重鎮,到 2030 年可能升到 39% 到 57%。
這些數字不代表 AI 一定會壓垮電網。它們真正說明的是:AI 的用電問題不是平均分布的全球百分比,而是集中在特定州、特定輸電節點、特定施工與許可流程上的局部壓力。
所以 Sachin 說,過去我們把能源想成供人類消耗,這個想法不再成立。未來能源也會供給數位勞動、代理型工作、科學研究與自動化組織。AI 不是只吃電,它會重新塑造電力市場。
Agent 讓運算圖變複雜了
ChatGPT 剛出現時,典型互動很簡單:使用者問一句,模型回一句。從電腦科學角度看,這是一個很簡單的 compute graph。
但 agent 不一樣。
Sachin 描述的 agent 不是「會講話的助理」,而是會閉環的系統。它不只是思考和建議。它會嘗試、看結果、修改、再試一次。寫程式時,它可能搜尋資料、讀專案、啟動虛擬機、跑測試、看錯誤訊息,再回到模型推論。做研究時,它可能查詢資料庫、整理文件、產出草稿、再根據結果修正。
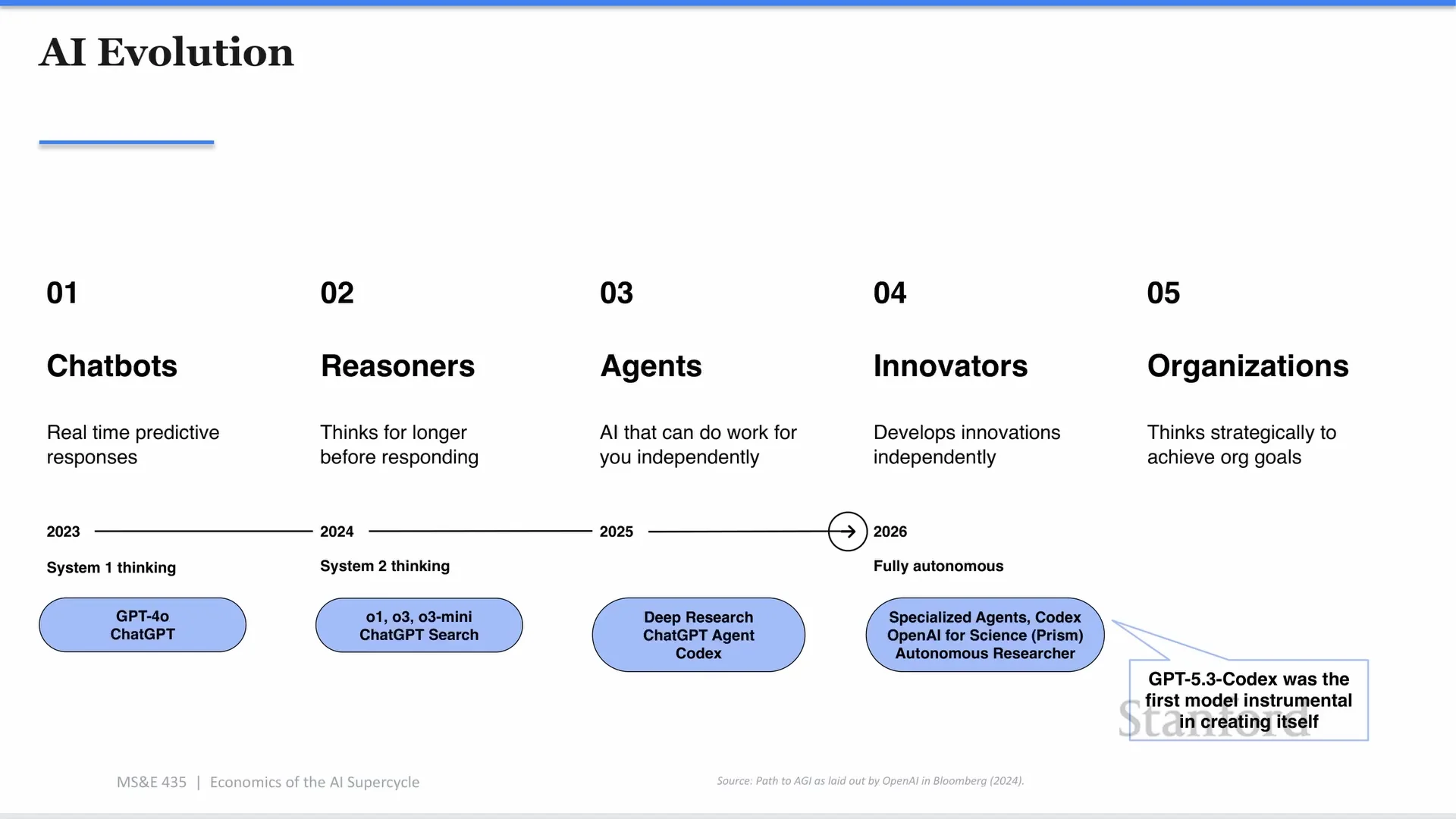
這個運算圖變成有向無環圖:推論呼叫、工具呼叫、資料庫查詢、搜尋、VM、測試環境,再回到推論呼叫。每個節點可能需要不同硬體、不同延遲要求、不同記憶體型態、不同調度策略。
這就是為什麼 Sachin 說,純 GPU 架構無法經濟地交付未來的 agent 體驗。未來需要異質運算(heterogeneous compute):GPU、CPU、專用 ASIC、低延遲推論晶片、長上下文記憶體架構,各自處理適合自己的工作負載。
OpenAI 與 Cerebras 的合作就是一個例子。OpenAI 公開表示,Cerebras 會提供 750MW 的低延遲 AI compute,分階段加入推論堆疊。Sachin 在官方聲明裡說,OpenAI 的 compute strategy 是建立有韌性的 portfolio,把正確系統匹配到正確工作負載。
這句話和課堂上的觀點完全一致。未來 AI 基礎設施的能力,不是誰買最多同一種晶片,而是誰能把不同工作負載切開,放到最合適的硬體與系統上。
目標不是讓 AI 很快,而是讓人類變成瓶頸
整場對談裡,最像產品哲學的一句話是:目標是讓 human 成為 bottleneck。
今天很多 agent 體驗還是反過來。你給它一個任務,它開始跑。你等太久,就切去做別的事。幾分鐘後它回來問你要不要批准、要不要改方向,你還得重新把上下文載回腦中。
這不是好的工作流。它打斷人的心流。
Sachin 說,真正成功的 AI 運算基礎設施,應該讓 AI 快到不斷問你下一步。人類花時間在判斷、方向、接受或拒絕,而不是等模型推論、等工具呼叫、等排程。
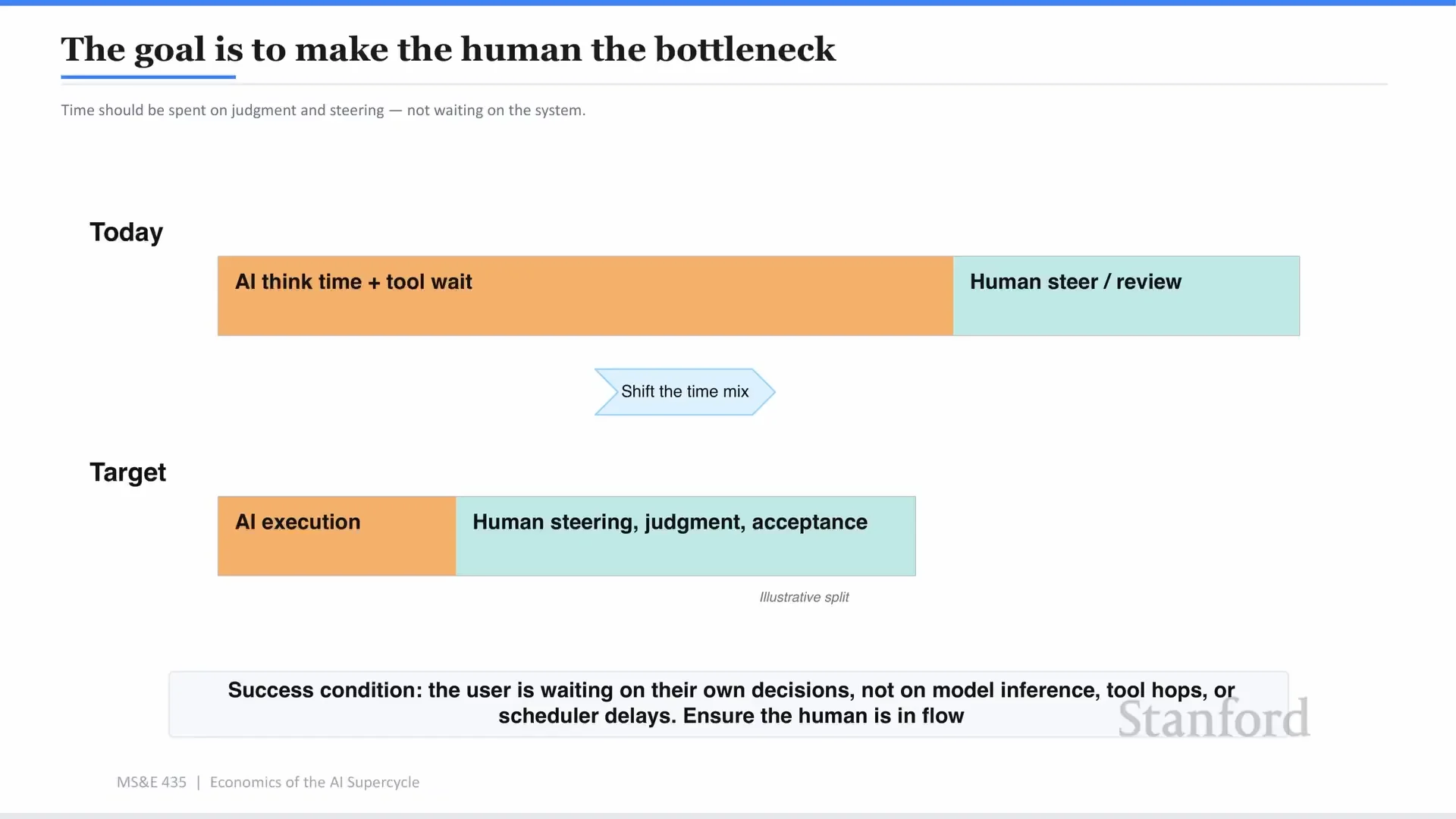
這裡的競爭會變得很細。不是只有「模型比較聰明」。還包括 time to first token、工具呼叫延遲、API overhead、上下文 pre-fill、負載平衡、快取、安全檢查、計費與後處理。
OpenAI 的工程文章提到,Codex agent loop 會在 API 服務、模型推論、客戶端工具執行之間反覆往返。當模型推論速度從每秒約 65 tokens 提升到接近 1000 tokens,API overhead 反而變成顯眼瓶頸。後來透過 WebSocket、快取、減少網路跳轉等方式,端到端 agent workflow 提升約 40%。
這正好印證 Sachin 在課堂上的說法:當堆疊某一層變快,其他層的低效率就會冒出來。AI 基礎設施會變成一場打地鼠遊戲。你修掉推論速度,API 變慢;你修掉 API,工具執行變慢;你修掉工具,使用者介面又變成瓶頸。
而這些幾十毫秒的差異,最後會反映在參與度、留存、營收上。網頁時代如此,agent 時代也會如此。
供應鏈不能單線依賴,因為世界沒有那麼多選擇
Apoorv 問到 NVIDIA、Amazon Trainium、Google TPU、各種 ASIC 的競爭時,Sachin 沒有直接選邊。他的重點是:世界需要更有韌性的 compute supply chain。
他認為,任何一個元件單線依賴都很危險。工作負載也會推動多樣化,因為未來的 agentic workload 不再只是單純 GPU 上的訓練或推論。
更深一層,他提到台積電晶圓分配的現實。台積電本身不會希望只依賴單一大客戶。晶圓會分配給不同公司。結果就是市場上會有多種 GPU 與加速器。Google、Amazon、OpenAI 或其他 hyperscaler,都必須學會使用不同晶片。
這不是偏好問題,是沒有選擇。
同樣地,當 Apoorv 問「基礎設施最大的未解問題」時,Sachin 指向邏輯與記憶體的晶圓廠產能。他提到台積電、三星、Intel、Micron、SK Hynix、Samsung,然後再往下挖到 ASML。整個供應鏈集中在少數公司,最深的瓶頸可能是微影設備。
這也解釋為什麼他對 Intel 的看法比市場敘事更複雜。他認為 Intel 有兩個順風:世界供應嚴重受限,任何能製造而不只是設計的公司都有價值;另外,agent 時代會讓 CPU 重新有角色。這不代表 Intel 一定勝出,執行仍然很難。但如果 AI 需求真的往 gigawatt-scale 走,美國本土先進製造能力就不只是企業策略,而是產業韌性。
真正被低估的,是最低層
課堂最後,Apoorv 問了一個創業與投資問題:AI 五層蛋糕裡,長期價值會在哪裡?
Sachin 的回答很有層次。他說,歷史會押韻。行動網路早期,錢先被電信商和基礎建設拿走,後來移到應用層,再移到雲端服務。AI 也可能如此。現在利潤在基礎設施層,但未來會往平台與應用移動。
可是當他被問到「你會 long 什麼」時,他反而選最低層。
原因很簡單:美國已經忘記如何大規模建造基礎設施。
他列出一串很不「AI 應用」的題目:變壓器、電池、發電、配電、冷卻、元件、材料、電晶體。這些才是被低估的層。因為它們同時需要技術與規模,一旦做出來,別人很難複製。
這對學生和創業者是很明確的訊號。AI 不是只有模型 wrapper,也不是只有套一層介面的 SaaS。Sachin 甚至說,他看空任何只是 model wrapper 的東西。更激進一點,他懷疑「app」這個概念本身會不會是未來的主要介面。人類可能不是打開一堆 app,而是直接要求 outcome。
如果這個判斷成立,應用層仍然有價值,但單純包模型的價值會被壓縮。真正能留下來的,要嘛掌握專有工作流、資料、分發與閉環,要嘛深入最底層,解決硬體、能源、記憶體、冷卻、編排、延遲這些難題。
AI 產業的關鍵指標,從參數量變成 time-to-compute
這場課最後回到 Stargate。一位聽眾問:OpenAI 要怎麼交付這麼多 compute?
Sachin 說,對他來說,Stargate 基本上就是他的工作。他給了一個非常硬的數字:以他們討論的規模,一吉瓦支出約 $70 billion。再加上一吉瓦約五十萬顆 GPU,這不是單純的資本支出故事,而是營運挑戰。
所以他的核心指標不是只有「amount of compute」,而是「time-to-compute」。
這個詞很重要。因為在 AI supercycle 裡,晚到的算力可能就不是同一種算力。模型架構在變,推論形態在變,agent 工作流在變,使用者需求也在變。晶片設計週期動輒三年,可是三年前 ChatGPT 才剛推出。以今天的速度,三年像一個世代。
因此,誰能更快把正確型態的算力設計、採購、建造、上線、穩定運作,誰就能更快把智慧變成產品,把產品變成收入,把收入再投入下一輪基礎設施。
這就是 AI supercycle 的飛輪。但它不是純軟體飛輪。
它需要電。需要土地。需要變壓器。需要晶圓廠。需要 ASML。需要冷卻。需要施工人力。需要資料中心不把電網拖垮。需要 API 和 agent runtime 跟上晶片速度。需要模型學會設計下一代模型要用的晶片和系統。
AI 看起來越像魔法,背後就越像工業。
這也是這場課最值得帶走的判斷框架:不要只問哪個模型最強,也不要只問哪個 app 最好用。要問三個更底層的問題。
第一,這個系統能不能取得足夠且準時上線的算力?
第二,這些算力能不能用足夠低的成本和延遲,交付到真實使用者手上?
第三,當工作負載從聊天變成 agent、從單次回答變成閉環執行,這套基礎設施還能不能跟著變形?
未來幾年,AI 競爭可能會繼續被包裝成模型排名、產品更新、價格戰。
但在更底層,真正的比賽是誰能把智慧變成可交付的工業產能。
那不是 demo。那是工程。
【資料來源】
- MS&E 435 | Economics of the AI Supercycle - Stanford 課程頁,說明課程定位與 Sachin Katti 的講者角色。
- Intel CTO and AI boss quits to join OpenAI - The Register,2025-11-11。用途:Sachin Katti 從 Intel 轉往 OpenAI 的背景。
- Building the compute infrastructure for the Intelligence Age - OpenAI,2026-04-29。用途:OpenAI 對 Stargate、10GW 與基礎設施夥伴生態的說明。
- Stargate advances with 4.5 GW partnership with Oracle - OpenAI,2025-07-22。用途:Oracle 合作、4.5GW、超過 2 million chips 等公開數字。
- OpenAI partners with Cerebras - OpenAI,2026-01-14。用途:750MW 低延遲推論合作與 workload matching 策略。
- Speeding up agentic workflows with WebSockets in the Responses API - OpenAI,2026-04-22。用途:Codex agent loop、推論速度、API overhead 與延遲優化。
- Energy demand from AI - IEA,2025。用途:資料中心用電量與 2030 年預測。
- Data centre electricity use surged in 2025 - IEA,2026-04-16。用途:2025 年資料中心用電、capex、供應鏈與能源瓶頸。
- EPRI: Data Centers Could Consume Up to 17% of U.S. Electricity by 2030 - EPRI,2026-02-26。用途:美國資料中心用電占比情境與州層級壓力。
- How Scaling Laws Drive Smarter, More Powerful AI - NVIDIA,2025-02-12。用途:pretraining、post-training、test-time scaling 的背景說明。
- Inference Scaling Laws - arXiv,2024/2025。用途:推論時計算與模型效能取捨的研究背景。
本頁由影片逐字稿、截圖與 AI 整理生成,內容可能需要回到原始來源查證。