MS&E435系列④:企業 AI 卡住,不是因為模型不夠強:Ali Ghodsi 拆開「context」這道牆
Ali Ghodsi 一開口,就先叫大家冷靜。
Ali Ghodsi 一開口,就先叫大家冷靜。
不是那種客套的冷靜,而是很直接的「你們不要被 Twitter 上每天的新恐慌牽著走」。在 Stanford MS&E435 第四堂課裡,Apoorv Agrawal 問他:現在 AI 變化這麼快,XAI、Cursor、OpenAI、Anthropic 都在打,Databricks 也從資料公司、lakehouse 公司,變成 AI 公司。你看到的 state of the union 是什麼?
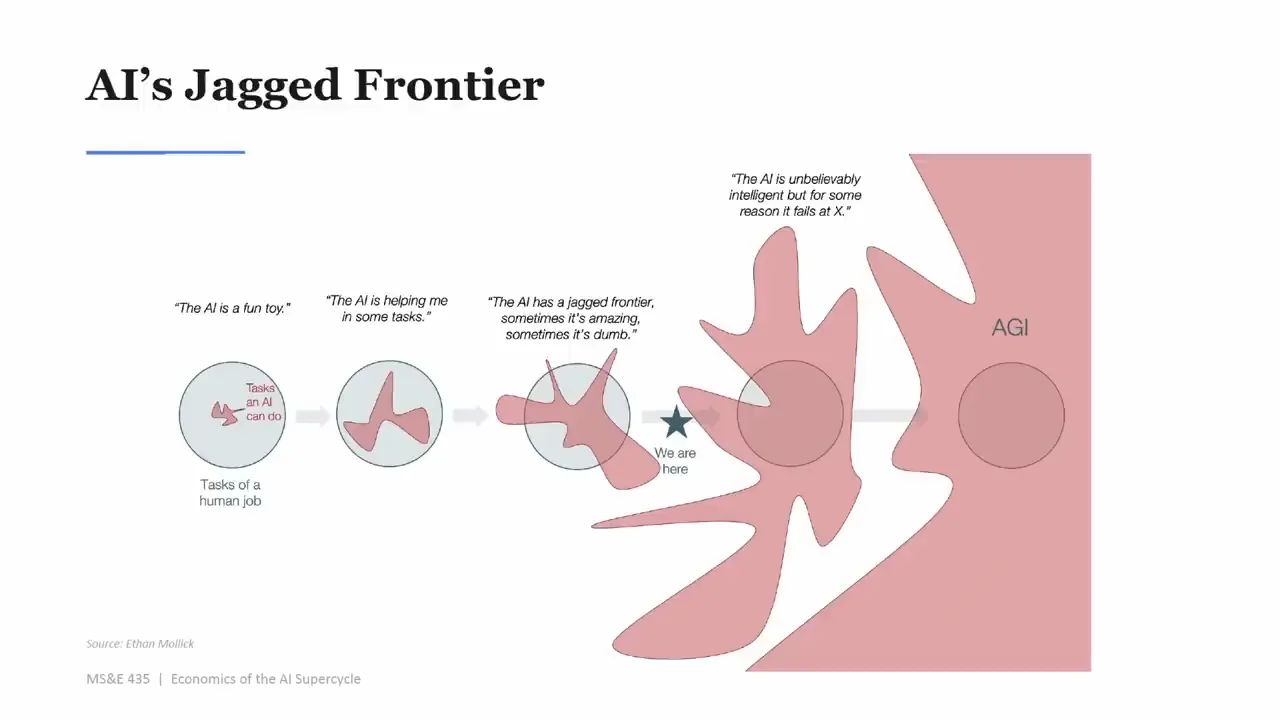
Ali 的答案很反直覺:別太焦慮。超級智慧的敘事被講得太神話了。大家一直移動 AGI 的定義,但如果你問「現在最強模型是否已經比很多你日常互動的人更聰明」,很多人其實會承認答案是 yes。
所以他說:我們已經有 AGI。
但下一句才是整堂課的重點。
如果 AGI 已經存在,為什麼企業裡還沒有到處都是 agent coworker?為什麼公司內部沒有突然變成自動化天堂?為什麼大家做了很多 POC,最後仍然看不到明確生產力?為什麼大型企業的日常工作,看起來還是像《Office Space》那種舊世界:人類搬報表、開會、查資料、問那個「什麼都知道」的 John 或 Jane?
Ali 的答案不是「模型還不夠聰明」。
他的答案是:模型缺 context。
真正的瓶頸不是智慧,是組織記憶
Ali 說,每家公司裡都有一個人,大家遇到問題就說:「去問 John」或「去問 Jane」。那個人可能待了 10 年、20 年、30 年。他知道流程怎麼走,知道例外怎麼處理,知道誰可以批准,知道某個客戶過去發生過什麼,知道系統資料哪裡不乾淨,也知道文件裡沒寫但大家默認的規則。
這些東西就是企業的 context。
今天的模型沒有這些 context。它可能會寫程式,會解數學,會讀文件,會生成報告。但如果它不知道公司真正如何運作,它就會犯很多蠢錯。不是因為模型笨,而是因為它像一個非常聰明、但剛入職第一天的人。你把他丟進公司裡,沒有 onboarding,沒有內部知識,沒有流程脈絡,沒有權限與工具,他當然做不好。
這也是 Ali 對 enterprise AI 的核心判斷:如果你想在世界上創造影響力,就想辦法把組織裡的 context 放進 AI。不是再做一個更炫的聊天框,也不是再買一個模型 API,而是把公司多年累積的流程、資料、判斷、權限和例外處理方式,變成 agent 能讀、能用、能行動的結構。
這句話把企業 AI 的問題從「AI 能不能」改成「組織願不願意重構自己」。
你可以把它想成這樣:模型是大腦,但企業流程是身體。現在很多公司買了一顆很強的大腦,卻沒有神經、手、腳、眼睛和肌肉。大腦再強,也只能在會議室裡回答問題,不能真正把事情做完。
為什麼 POC 會失敗:因為大家把電動馬達塞進舊工廠
Ali 用一個歷史類比解釋這件事。他提到 Paul David 的經典文章〈The Dynamo and the Computer〉。
電力剛出現時,工廠沒有立刻變得更有效率。很多工廠只是把蒸汽引擎換成電動馬達,但仍然沿用舊的 line shaft 結構:一根主軸帶動整棟工廠的皮帶和機器。結果生產力沒有大幅上升。
真正的生產力提升,是後來大家重新設計工廠。既然電力可以分散供應,工廠就不用擠在城市裡,不用圍繞一根主軸設計,不同生產線也能用不同速度運轉。電力的價值不是「替換蒸汽引擎」而已,而是讓工廠 layout 被重新想像。
PC 也一樣。Solow 那句名言大意是:電腦到處都看得到,唯獨生產力統計裡看不到。原因不是電腦沒用,而是很多公司一開始只是把 PC 當打字機。打完列印出來,放進資料夾,再找人分類。工作流程沒有變,工具再新也只是比較貴的打字機。
Ali 說,AI 正在重演這件事。
很多企業把 AI 插進舊流程裡,期待生產力突然暴增。客服流程沒改,權限沒改,資料沒整理,測試方式沒改,審批流程沒改,然後問為什麼 agent 不好用。這就像把電動馬達裝進蒸汽工廠,再抱怨電力沒有帶來革命。
企業 AI 的關鍵不是「把 AI 加到現有流程」。關鍵是問:如果一開始就有 AI,我們會怎麼設計這家公司?
這句話聽起來很大,但 Ali 用 Databricks 自己的 connector 團隊講了一個很小、很具體的例子。
Databricks 的 connector 例子:兩天寫出 toy,九個月才叫 production
Databricks 會替客戶連接 Salesforce、Workday、NetSuite 等系統,把資料整合到平台裡,再做分析和 AI。過去,Databricks 建一個 production-grade connector 大約要三個 quarter,也就是九個月。
Ali 自己用 LLM 試了一下,覺得兩天就能寫出一個 connector。於是他去問團隊:為什麼你們要九個月?
團隊回去分析,最初的答案是:AI 可以幫忙,但大概只能省一個半月。九個月變七個半月。原因也很合理:Ali 兩天寫出的是 toy,不是 production code。真正上線要安全、穩定、支援客戶回饋、處理例外、測試不同系統、文件化、維護,這些都不是模型一口氣寫完就算數。
但故事沒有停在這裡。Ali 又找了一位更 first-principles 的同事重新看流程。那位同事發現,瓶頸不是 coding 本身,而是整個工作流程。
第一個 quarter 被產品需求卡住。高薪、聰明的 PM 會去拜訪客戶,收集需求,最後寫出 60 到 80 頁規格文件。這件事不能靠更快寫程式解決,因為程式還沒開始寫。
第二個瓶頸是測試環境。要測 connector,就要架 Salesforce、Workday、NetSuite 等外部系統。這些不是 Databricks 自己的產品,團隊不熟,準備環境很慢。
第三個瓶頸是 bus factor。每個 connector 只有一個人負責。那個人請假、生病、卡住,整個專案就停。
最後他們不是換模型,而是換流程。需求收斂從一季縮到一週,先快速寫下目前知道的東西。因為 AI 讓重寫成本變低,錯了可以更快改。外部測試環境交給更擅長的供應商處理,用錢換時間。人力配置從一人一個 connector,改成七個人共同做七個 connector,降低單點風險。
結果:一個 quarter 做出七個 connector。
這段最有價值的是 Ali 的結論:這件事和 GPT-7、Opus 6 或更強模型沒有太大關係。真正的改善來自 human refactoring 和 process change。
翻譯成白話:AI 讓寫程式變快,但公司如果還用舊方式收需求、測試、分工和審批,速度仍然會卡在舊流程上。
軟體沒有死,但 UI 護城河正在塌
Apoorv 接著問一個資本市場很關心的問題:software is dead 嗎?
Ali 的回答很乾脆:如果所有軟體都死了,那 OpenAI、Anthropic、NVIDIA 也死了。OpenAI 和 Anthropic 本質上也是一群研究員和工程師寫軟體。NVIDIA 的晶片設計也高度依賴軟體。說「軟體死了」太粗糙。
但他也承認,軟體市場確實變了。兩件事同時發生。
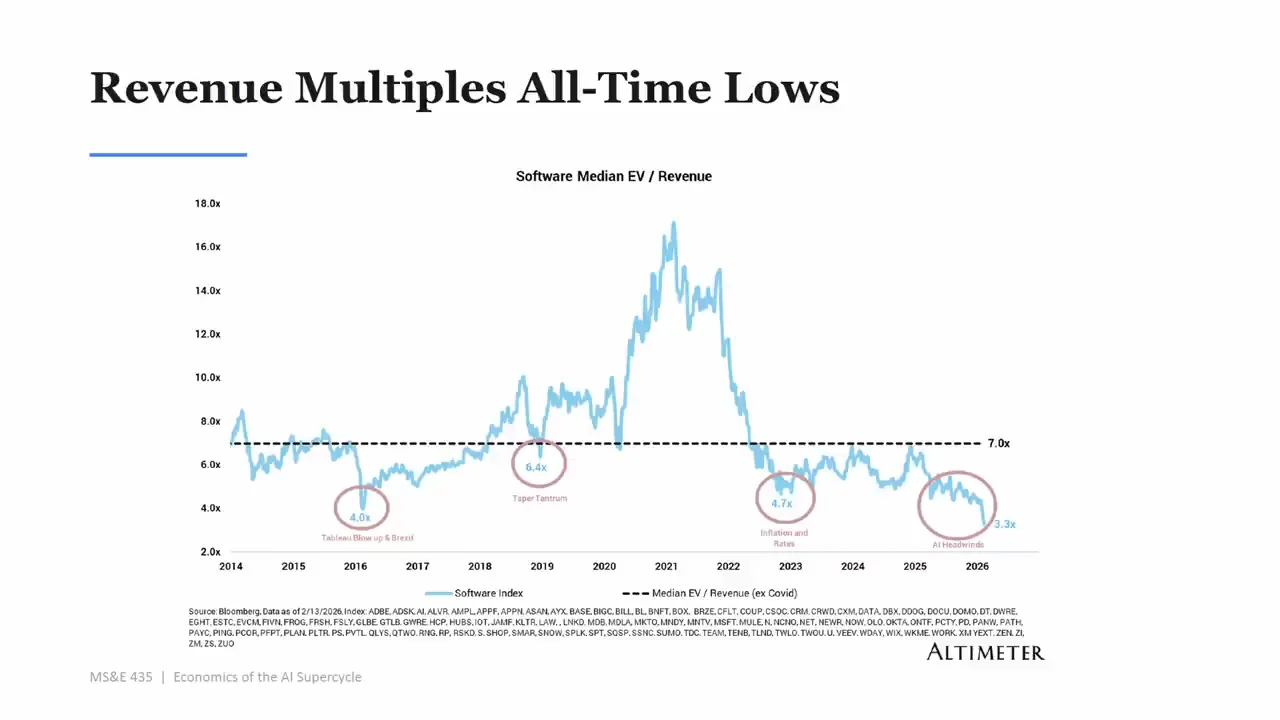
第一,進入門檻下降。AI 讓寫軟體變得更便宜、更快。過去需要一整個工程團隊才能做的東西,現在小團隊可以更快做出原型。這會讓競爭變多。
第二,切換成本下降。過去軟體的 moat 很大一部分來自 UI 習慣。人們學會 Salesforce、SAP、ServiceNow、某套 CRM 或財務系統後,就不想換。換系統不只是資料搬移,也是重新訓練人。
但如果未來你主要是對 agent 說話,UI 的差異會變得不重要。你不需要知道 Salesforce 的按鈕在哪裡,也不需要學 Outlook 或 Gmail 的細節。你只要說你要什麼,agent 去操作底層系統。這會削弱很多 SaaS 公司長期累積的 UI moat。
TechCrunch 今年對 Ali 的訪談也延伸了這點:SaaS systems of record 不會立刻被拔掉,因為資料和核心流程很難搬。但自然語言介面會讓產品變得像水管。使用者不再花多年訓練自己成為某個介面的專家,agent 可以跨系統操作。
所以軟體不是死。死的是只靠舊介面和舊工作流活著的軟體。
真正安全的軟體公司有其他 moat:專有資料、規模經濟、品牌、信任、安全認證、深度流程整合、客戶關係。Ali 引用 Hamilton Helmer 的《7 Powers》脈絡:護城河不是只有程式碼。程式碼變便宜後,其他力量反而更重要。
企業 AI 哪裡有效?先看 context 是否進得去
Apoorv 問 Ali:你們有 20,000 多個客戶,這是觀察企業 AI 的好樣本。哪些地方 AI 正在打全壘打?哪些地方還很粗糙?
Ali 先說:這不是 AI 的錯。
大多數公司現在只是讓 AI 幫某些任務,不是真的把 agent 放進核心流程。支援客服就是好例子。很多人以為 support 會最先被 AI 吃掉,因為客服看起來像問答。但 Ali 說,support 其實很難,尤其是 Databricks 這種高技術產品。
客戶打給 support,不是因為他們不知道按哪個按鈕。通常是機器學習模型 F1 score 不對、資料流程卡住、平台配置有奇怪問題。這些客戶本身就是高薪、受過訓練的技術人員。他們已經試過很多方法才來求助。這時客服不是 FAQ,而是專家診斷。
如果 AI 有 Databricks support engineer 的完整 context,也許能做。但現在多數模型沒有。它不知道這個客戶的設定,不知道過去 ticket,不知道內部 workaround,不知道某個版本的 bug,也不知道公司裡某位老員工腦中的暗知識。
這和 OfficeQA Pro 的研究結果呼應。那個 benchmark 測的是企業文件上的 grounded reasoning。結果顯示,前沿模型只靠自身知識或 web 表現很差,就算直接給文件 corpus,仍有大量問題解不好;把文件轉成更結構化的 representation,平均表現才明顯改善。這不是模型完全沒能力,而是 enterprise context 的格式、結構、檢索、權限、推理鏈都還沒準備好。
企業 AI 的下一階段,不是把所有文件丟進向量資料庫就結束。它要把資料變成 agent 能可靠使用的工作記憶。
為什麼 governance 和 evaluation 不是合規廢話
Databricks 2026 State of AI Agents 的外部整理提到幾個數字:報告基於超過 20,000 個組織的匿名資料,其中包含超過 60% 的 Fortune 500。多 agent workflow 在四個月內成長 327%。77% 客戶使用兩個以上模型家族。使用 AI governance 的企業,把 AI 專案推進 production 的數量是其他企業的 12 倍;使用 evaluation tools 的企業,production 專案數是 6 倍。
這些數字很適合放進 Ali 的框架裡理解。
企業不是缺 demo。企業缺的是能上 production 的系統。Demo 可以很酷,production 要回答很多無聊問題:誰能看什麼資料?模型錯了誰負責?輸出怎麼測?資料 lineage 怎麼追?agent 能不能執行動作?執行前需不需要 approval?怎麼 rollback?敏感資料會不會外洩?
所以 governance 和 evaluation 不是法務部門拖慢創新的東西。它們是 enterprise AI 真正能跑起來的基礎設施。
這也是 Databricks 和 OpenAI 合作 Agent Bricks 的意義。外部公告說,OpenAI 模型會原生進入 Databricks Data Intelligence Platform 和 Agent Bricks,讓企業在受治理的資料上建置、評估、擴張 AI apps 和 agents。這件事的商業邏輯很清楚:模型要進企業,不能只靠聊天框。它要進到資料、權限、治理、MLOps 和 workflow 已經存在的地方。
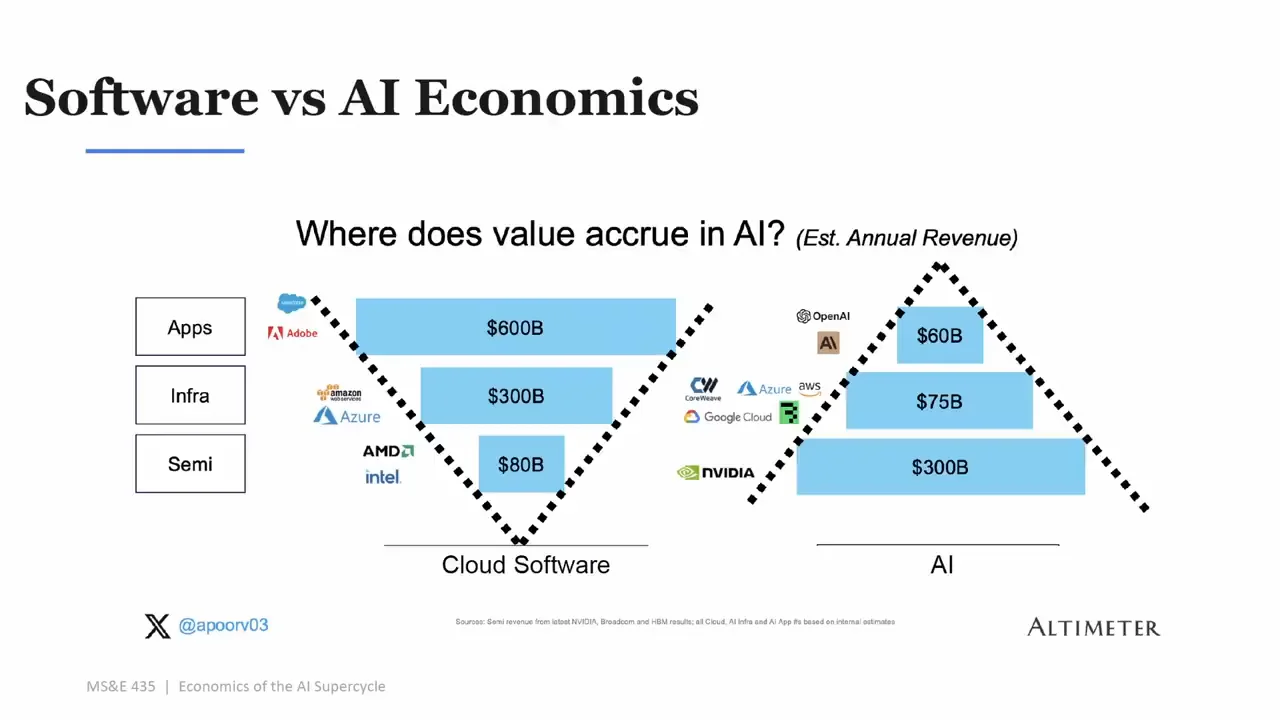
誰能把模型接到企業資料和流程,誰就比單純提供模型 API 更靠近價值。
價值會往上移:模型層像雲,應用層才可能出現怪物公司
Apoorv 問 Ali,如果把 $100 投在 AI stack 的不同層:energy、chips、infra、model、apps,長期看你會押哪裡?
Ali 說,應用層會贏。
他的理由來自網路時代的經驗。早期大家以為最難、最重要的是 networking。Ali 自己博士時代就在做 multicast。當時很多聰明人都覺得,未來全世界會同時看直播、看球賽,如何高效把同一份資料送給很多人,是網路最重要的問題。結果光纖部署太多,頻寬成本暴跌,multicast 變成沒人記得的問題。
真正的大公司反而長在奇怪的應用上:賣書的 Amazon、叫車的 Uber、出租房間的 Airbnb、發短文字的 Twitter。如果你在 2002 年用白話描述這些點子,很多人會覺得很蠢。但它們才是真正吃掉價值的應用。
Ali 認為 AI 也會如此。今天大家盯著 NVIDIA、OpenAI、Anthropic、DeepMind、chips、frontier models。這些當然重要,但長期最大公司可能出現在大家現在覺得無聊或困難的應用場景。
他點名兩個:healthcare 和 education。
Healthcare 約占美國 GDP 的 17% 到 18%。人們對健康和家人生命的付費意願很高,而現有體驗並不好。如果有一家公司真的看過上億病人的資料,理解你的基因、病史、風險、治療反應,能給你更好的照護,那可能是兆美元公司。
Education 在 VC 圈長期被視為難投資、難變現。但 Ali 反過來看:大家都有孩子,也在意孩子學什麼、怎麼學、是否具備未來能力。教育甚至能影響選舉和文化戰。如果 AI 能真的提供更好的教育成果,這個市場不該被低估。
他的判斷是,模型層會有價值,但會越來越像 cloud 或 token factory。規模很大,玩家不多,毛利和營業利益率會被競爭壓低。開源模型也會持續施壓。真正的厚價值,會往應用、資料、流程和使用者結果移動。
給學生的建議:不要追 multicast
課尾 Ali 給學生的建議很簡單:不要被恐懼牽著走,不要只追今天最吵的題目。
他回憶自己博士時代也曾焦慮。網路正在改變世界,大家都覺得 multicast 是最重要問題。結果那不是問題。Airbnb 也不是因為 2009 年突然有了什麼 2001 年沒有的技術才成立。只是 Brian Chesky 遇到一個真實痛點,想到一個好點子。
好點子很難。人類其實很不擅長想好點子。
所以 Ali 建議學生要拉長時間尺度。像 Bezos 當年在華爾街看到網路是 secular trend,沒有一開始就做很炫的事情,而是從最無聊的書開始。書是標準品,容易上網賣,逐年押對大方向,最後才變成 everything store。
這對 AI 時代的創業者很有提醒。今天最吵的是模型、晶片、agent benchmark、誰融了多少錢、誰發布新模型。但下一個真正的大公司,可能不是今天 Twitter 上最熱門的題目。它可能是某個真實世界痛點,剛好因為 AI 變得可解。
別追 multicast。找長期趨勢裡真正沒被解好的問題。
這堂課真正回答的是:企業 AI 的錢會流向哪裡?
Class #4 的表面主題是 enterprise AI。更深的問題是:AI stack 的價值會流向哪裡?
Ali 的答案很清楚:
模型已經夠強。至少強到可以開始重構企業流程。問題是企業還沒準備好讓模型工作。
SaaS 不會死。系統記錄、資料、客戶、信任和規模仍然有價值。但只靠 UI 習慣、舊流程和十年沒變的產品活著,會很危險。
Agent 不會靠魔法進 production。它需要 context、governance、evaluation、workflow redesign 和資料平台。
模型層會有價值,但會越來越像規模經濟生意。真正厚的價值,會在能把 AI 變成具體結果的應用層。
這堂課最反直覺的一句話,可以這樣總結:
企業 AI 不是缺智慧。企業 AI 缺的是把智慧接上組織的身體。
只要 context 還卡在人腦裡,只要流程還是蒸汽工廠,只要資料還是散在各系統,只要 production 仍然沒有治理與評估,模型再強也只能做 demo。
下一波企業 AI 贏家,不一定是喊 AGI 最大聲的人。會是那些能把組織裡的 John 和 Jane、資料庫、工作流程、權限、評估、客戶回饋和 agent 行動全部接起來的人。
這聽起來不性感。
但 Amazon 一開始也只是賣書。
【資料來源】
- 課堂紀錄:Stanford MS&E435 Class #4, Apoorv Agrawal with Ali Ghodsi。用途:主要論點、企業 context、SaaS 判斷、connector 案例、AI stack 價值判斷。
- MS&E 435 | Economics of the AI Supercycle - Stanford 課程官方頁。用途:課程定位與 Ali Ghodsi 講者背景。
- Class #4 | MS&E435 Fact Check - 用途:Class #4 主題、講者主張與外部摘要對照。
- TechCrunch: Databricks CEO says SaaS isn’t dead, but AI will soon make it irrelevant - 用途:Ali 對 SaaS、自然語言介面、Databricks AI 收入與 Lakebase 的外部訪談。
- Intelligent CIO: Databricks report reveals rapid rise of multi-agent AI systems in the enterprise - 用途:Databricks 2026 State of AI Agents 的多 agent、governance、evaluation 數據。
- OfficeQA Pro: An Enterprise Benchmark for End-to-End Grounded Reasoning - 用途:企業文件推理與 context bottleneck 的研究佐證。
- Databricks and OpenAI Launch Partnership for Agent Bricks - 用途:Agent Bricks、OpenAI 模型、governed enterprise data 的產品方向查核。
本頁由影片逐字稿、截圖與 AI 整理生成,內容可能需要回到原始來源查證。