MS&E435系列①:AI 的錢到底在哪裡?史丹佛第一堂課把「超級循環」拆成一張殘酷損益表
第一堂課,Apoorv Agrawal 沒有先談模型架構,也沒有急著講 prompt engineering。
第一堂課,Apoorv Agrawal 沒有先談模型架構,也沒有急著講 prompt engineering。
他先問了一個更像投資人、創業者、CFO 會問的問題:
AI 的錢在哪裡?
投影片上的正式說法是:「Where does value accrue in AI?」價值會累積在 AI 堆疊的哪一層?但這句話翻成白話,其實更直接:誰在收錢?誰在賺毛利?誰只是替別人墊算力成本?誰看起來最靠近使用者,卻未必拿得到最大的經濟利益?
這就是史丹佛 MS&E 435《Economics of the AI Supercycle》第一堂課的主軸。課程名稱是「Economics of the AI Supercycle」,Lecture 1,講者是 Apoorv Agrawal。課表安排從半導體、GPU 經濟、能源、AI factories、企業 AI、frontier lab、模型、應用、agent monetization,一路講到 AI in Life Sciences。換句話說,這不是一門「AI 很厲害」的導論課,而是一門把整個 AI 產業鏈攤開來算帳的課。
最有趣的是,Apoorv 一開始就把學生拉回一個五年後才會發生的場景。他說,五年後大家會問:「你當時有看出來嗎?」你會希望自己能回答「有」。這不是單純的時代感召。它更像一句提醒:你現在站在 ChatGPT 爆發後、產業板塊還在形成的早期階段。如果你之後要創 AI 公司、投資 AI 公司,或加入一家 AI 公司,你至少要知道這個產業的物理定律。
所謂物理定律,不是指 Transformer 的數學,而是指商業上的約束。
毛利率、資本支出、推論成本、訓練成本、雲端定價、晶片供給、使用者付費率。這些才是這堂課真正想追的東西。
這門課的核心:不是 AI 會不會成功,而是價值會流向哪裡
第一堂課的 agenda 很簡單:Introduction、Course Info、Quiz,以及「Where will value accrue in AI?」前三項像行政流程,第四項才是整堂課的拳頭。
後續每一週都對應 AI 堆疊的一個關鍵層級。4 月 9 日講 Silicon 和 GPU Economy,講者包含 NVIDIA 與 Altimeter;4 月 16 日講 Energy,主題是 gigawatt scale 的 AI factories;4 月 23 日講 Infrastructure、Enterprise AI 與 Service as a Software;4 月 30 日是 frontier lab case;5 月 7 日談企業內部知識;5 月 14 日談 applied AI 與 agent monetization;5 月 21 日談 coding AI 與軟體未來;5 月 28 日談生命科學裡的 AI。
這個課表本身就是一張 AI 經濟地圖。
它從最底層的能源、晶片、資料中心開始,往上走到模型、企業知識、應用、agent,再走到垂直產業。Apoorv 在口述裡說,接下來會有橫跨整個 stack 的領導者來上課,從 semiconductors 到 infrastructure,到 energy,到 models,再到 applications and agents。這句話其實透露了課程設計:每一週不是單純介紹一家熱門公司,而是把一家公司的位置放回產業堆疊裡問,它在哪一層?它收什麼錢?它的成本結構長什麼樣?它會被上游或下游吃掉嗎?
這也是他為什麼一再強調,學生要問對問題。
如果你只問「AI 模型是不是更強了」,答案很容易樂觀。如果你問「哪一層能長期留下超額利潤」,答案就複雜很多。模型可以變強,但模型公司不一定最賺錢。應用可以爆紅,但應用公司不一定有軟體時代的毛利。晶片公司看起來離終端使用者最遠,卻可能在早期拿走最多現金流。
這堂課的第一個重要視角,就是把 AI 從「產品體驗」拉回「產業損益表」。
為什麼要修這門課:因為這可能是最大的一波,但最大不代表人人賺錢
在「Why take this course?」那一段,Apoorv 把 AI 放進一條科技週期線:PC / Server、Desktop Internet、Mobile Internet、Data Explosion + Cloud、Gen AI。旁邊散落著 Microsoft、Google、Amazon、AWS、Google Cloud、NVIDIA、OpenAI、Snowflake、Databricks、Meta、Uber、Airbnb 等公司名稱。
這張投影片的訊息很明確:AI 被放在 PC、網路、行動、雲端之後,作為下一個大週期。
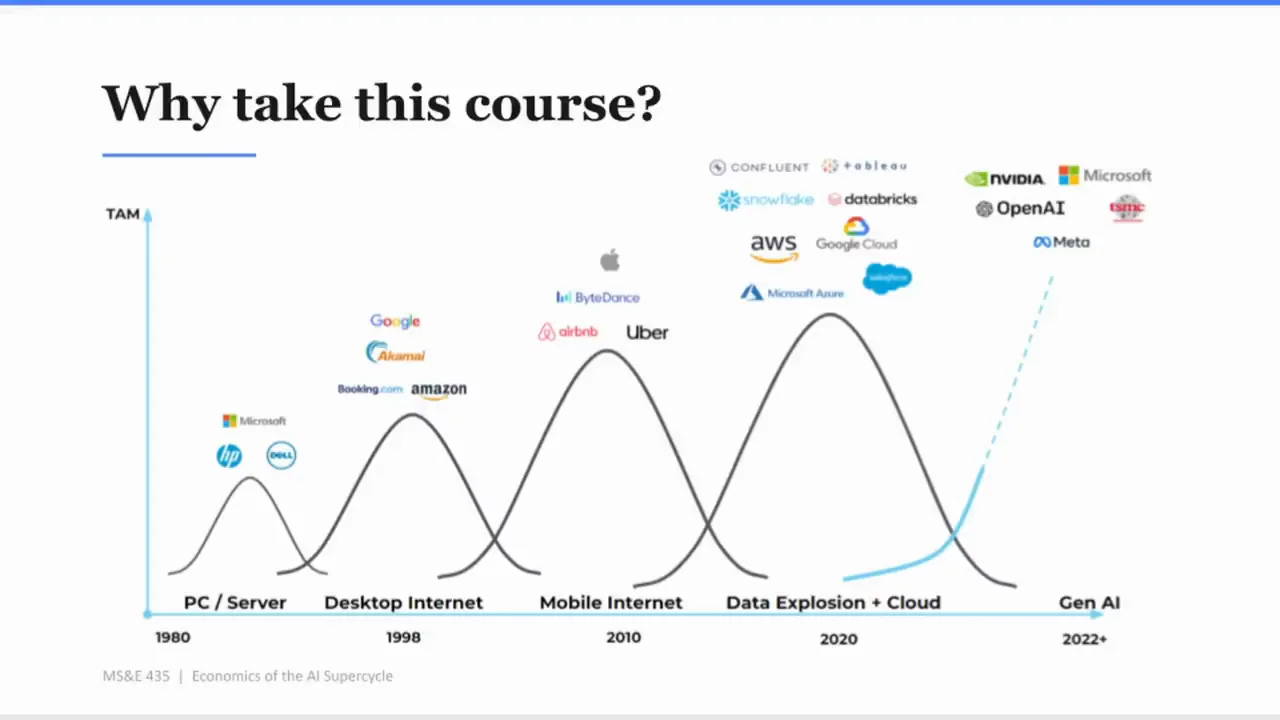
但 Apoorv 的講法沒有停在「這是大趨勢」。他說,過去他每年回校園談正在發生的事,通常是在尋找人才的脈絡下。後來他意識到,這是一個太大的 super-cycle,而且他沒有找到一門課能以他想要的深度拆解這件事。這段話很重要,因為它說明這門課不是為了追熱點,而是為了建立判斷框架。
他給學生的想像很直接:你們一半的人會創辦 AI 公司,另一半會投資 AI 公司。至少你應該知道,如果你募到 A 輪,錢要花在哪裡。更低標準也要知道,哪些事不要做。
這是創業者最容易忽略的地方。當一個週期足夠大,大家會以為只要站進去就會贏。但歷史不是這樣。網際網路泡沫裡,很多公司消失了,Google 留下來。行動網路裡,很多 app 曾經爆紅,Apple 和少數平台留下來。雲端裡,很多公司受惠,但真正掌握底層規模經濟的是 AWS、Azure、GCP 這樣的寡占者。
所以 AI 如果真的是超級循環,問題也不是「會不會有贏家」。
問題是,你站的位置是不是贏家的位置。
第一張三角形:AI 現在不是倒金字塔,而是底層很肥
整堂課最重要的視覺,是 Apoorv 一直回到的那個 triangle。投影片反覆出現「Where is the $ in AI today? And in 10y?」以及「Where does value accrue in AI?」底下分成 Apps、Infra、Semis、Cloud、AI 等層級,旁邊標出不同年度、不同估算口徑下的 revenue。
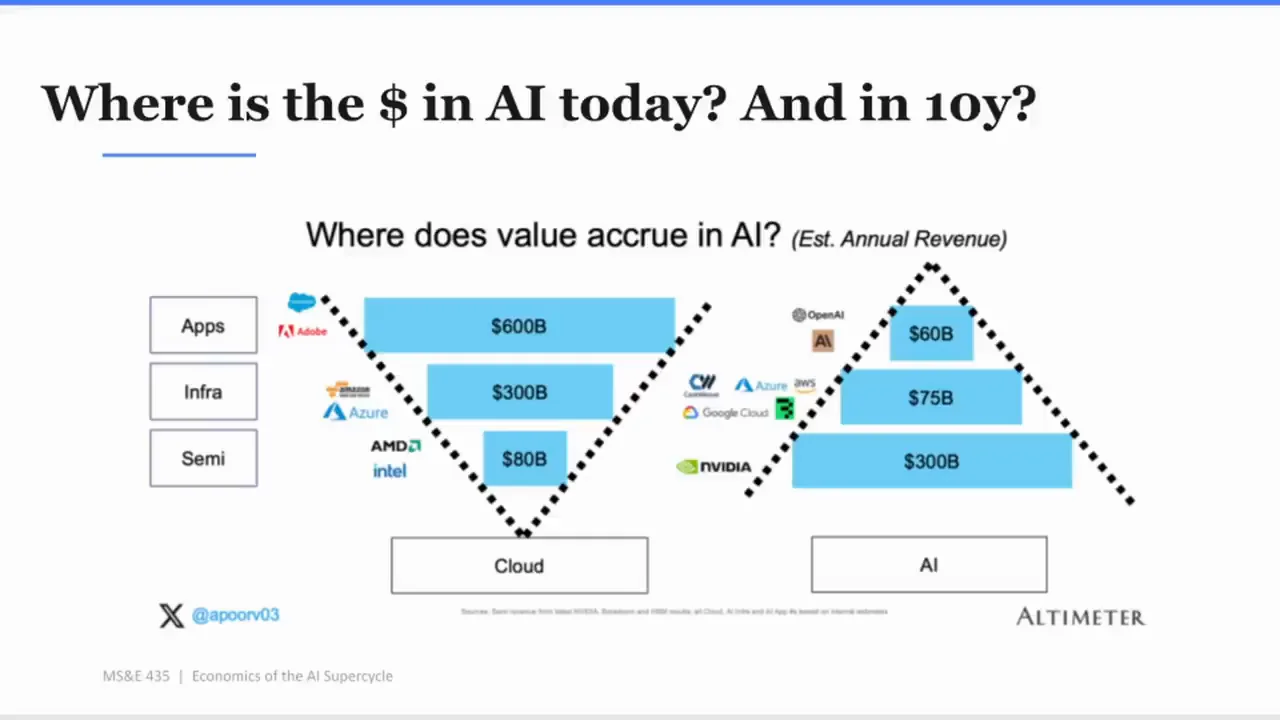
他把這張圖拿來和雲端、網路、行動週期比較。一般成熟科技週期裡,價值常常往上層走。最接近使用者、最掌握分發、最能包住商業模式的公司,最後拿走很大一部分價值。但 AI 現在看起來不太一樣。它不像一個已經翻轉的倒三角形,反而更像底層很厚、上層還薄的三角形。
課中引用的數字有些來自不同圖表和不同來源,有 Statista、Bloomberg、company filings,也有 top-down 或 internal estimates。這些數字不能當成 audited industry total,但方向很一致:AI revenue 在 2024 到 2026 之間大幅增加,投影片甚至寫著「AI Revenue has grown 5x in 2y!」總量從約 900 億美元到約 4,350 億美元。但 Apoorv 補了一句關鍵話:儘管成長很猛,形狀沒有太大變化;新增的大約 3,500 億美元收入裡,有相當大一部分直接流向 semis。
翻譯成白話:
AI 變大了,但錢還是很大比例流到底層。
這就是第一堂課最反直覺的地方。大家在媒體上看到的是 ChatGPT、Gemini、Claude、Perplexity、Cursor、各種 AI agent。但如果你追收入和毛利,很多價值先被資料中心、GPU、晶片、雲端基礎設施吃掉。使用者看到的是應用,企業付帳時看到的是 token、API、cloud bill,最後底層供應商收到的錢可能比應用層更確定。
這不是說應用層不重要,而是說應用層還沒有證明自己能像傳統軟體一樣留下漂亮毛利。
軟體曾經能吃掉世界,因為邊際成本幾乎是零
Apoorv 在第 12、13 張投影片附近講到整堂課最核心的一句話:傳統軟體之所以能吃掉世界,是因為你可以寫一次軟體,分發給幾百萬人,執行那個軟體的邊際成本接近零。很多軟體公司因此能跑出 80%、甚至 90% 的 gross margin。
這是 SaaS 世界的基本信仰。
你先投入研發,把產品做出來。之後每多一個使用者,伺服器成本會增加,但不是線性增加。收入增加得比成本快很多,毛利率就漂亮。這也是為什麼投資人願意用高倍數買軟體公司,因為一旦產品找到市場,後面的規模經濟很甜。
但 AI 應用不一定能直接套這個公式。
講者明確說,AI application 的 incremental user 不是 free,也不是 marginally free。每多一個使用者,就要 burn GPUs。這句話很短,但它拆掉了很多 AI app 估值裡的偷懶假設。你不能只拿「軟體公司」的估值框架來看 AI 應用,因為 AI 每一次互動都可能帶著推論成本。產品越好用,使用者越常用,帳單也越常跳。
這就是為什麼他會提到 Cursor 這類大規模 AI 應用可能已經有很大 revenue,但仍然面臨 profitability 壓力。不是因為產品沒需求,而是因為需求本身會燒成本。
如果傳統軟體的夢是「寫一次,賣無限次」,那 AI 應用的現實更像「每服務一次,就付一次算力稅」。
這不是壞事,但它完全改變了商業模型。
AWS 類比:底層建設可能需要八年,市場會先懷疑你是不是瘋了
在學生討論為什麼 AI 三角形還沒翻轉時,Apoorv 補了一個雲端的歷史類比。他提到 AWS 2004 年開始,2010 年有 Netflix 這樣的第一批客戶,2012 年 Amazon 才全面轉向 AWS。從破土動工到真正變成核心能力,中間大約八年。
這段看似是在講雲端,其實是在提醒大家:基礎設施週期和應用收入週期,時間感不一樣。
半導體、資料中心、電力、冷卻、網路互連,不是今天看到需求、明天就能供給。投影片和口述都一直在講 capex cycle。你今天蓋的是未來五年、六年的容量。這種投資很像鋪鐵路。鐵路一開始看起來會過度建設,資本密集公司市值先膨脹,市場會懷疑這些錢能不能回收。等到上層應用真的起來,底層容量才變成收租資產。
所以 AI 現在的狀態,可能有兩種解讀。
第一種是樂觀版:我們只是還在早期。底層先建,應用後來追上。等推論成本下降、使用場景成熟、企業採用擴大,價值會慢慢往上層移動。今天看起來偏向 semis 的三角形,未來會變得更像 cloud software。
第二種是保守版:AI 的底層成本結構可能會讓這個三角形維持很久。因為要把 substrate 做對很難。只要每一次使用都要燒貴的算力,應用層就很難像傳統軟體那樣輕。
Apoorv 自己的語氣偏向第一種,但不是天真樂觀。他說他認為 AI 不太可能只是 fad,也不太可能失敗。但他也猜測,這種底層偏厚的 equilibrium 可能比他原本預期更久。這句話值得記住:AI 會成功,不代表應用層很快就會賺大錢。
「你是功能還是平台?」中間層的殘酷問題
課中談到 inference layer 和 infrastructure startups 時,Apoorv 提出另一個很實用的問題:你到底是 feature,還是 platform?
這句話對 AI 基礎設施公司尤其刺耳。
今天很多 AI infra 新創看起來很有道理:模型部署、推論加速、資料管線、觀測、agent 工具、RAG、workflow、evaluation。每一個單點問題都真實存在,也可能有早期客戶。但如果你把問題拉長到五年,最危險的追問會變成:為什麼這不會變成 AWS、Azure、GCP 或 frontier lab 自己的一個功能?
這就是中間層的競爭強度。
投影片裡的 infra segment 被講者稱為競爭最激烈、代謝率最高、也最不穩定的地方。這裡會有很多公司成立,也會有很多公司被併購。因為大家都知道,AI 應用要長大,必須有更便宜、更穩、更可觀測、更好部署的基礎設施。但同時,hyperscalers 也不會放棄這層控制權。
對創業者來說,這不是叫你不要做 infra。
它是在提醒你,做 infra 必須很早回答邊界問題。你解的是一個雲端巨頭不想解、解不好、或因為中立性不能解的問題嗎?你有沒有跨平台價值?你的產品是越多客戶用越強,還是雲端廠一複製就結束?你掌握的是 workflow、資料、效能,還是只是 API 包裝?
如果回答不出來,你可能不是平台。
你只是下一季 release note 裡的一個小功能。
Google 的例子:大公司不能只放在一層,要拆成事業單位看
有學生問 Google 應該放在三角形哪一層。因為投影片把 Google Cloud 放在中間層,但 Google 同時有 Gemini,也有自己的 TPU。
Apoorv 的回答很務實:像 Google 這種大型 conglomerate,應該拆成 business units。TPU 算 semis,GCP 算 infrastructure,Gemini 算 apps。
這個回答表面上是在分類 Google,其實是在建立一個分析大公司的方法。
AI 時代的大公司很可能不是單層玩家。Google 有晶片、有雲、有模型、有應用、有分發。Microsoft 有雲、有 OpenAI 關係、有 Copilot、有 enterprise distribution。Amazon 有 AWS、有自研晶片、有電商入口、有企業客戶。Meta 有模型、有社群分發、有 MTIA。NVIDIA 也不只賣 GPU,它往 DGX Cloud、vertical apps、完整軟硬體 stack 前進。
所以問「Google 是不是 AI 應用公司」太粗糙。
更好的問法是:Google 的哪個業務單位在哪一層賺錢?哪一層是成本中心?哪一層提供分發?哪一層防止被供應商掐住脖子?哪一層可能成為新的利潤池?
這也是 AI 經濟比上一波軟體更複雜的地方。過去你可以說某家公司是 SaaS、social、cloud、consumer app。但在 AI 週期裡,真正有戰略能力的公司,往往會跨層整合。問題不是它在哪一層,而是它能不能把多層整合成利潤。
ASIC、TPU、MTIA:真正能改變三角形的,不一定是下一個 chatbot
當學生問這個三角形會不會翻轉時,Apoorv 提到幾個可能的 unlock。其中最重要的一類,是 hyperscaler 的 ASIC program,例如 Google TPU、Meta MTIA,以及 Amazon、OpenAI、Microsoft 等公司的自研晶片或實驗室。
這點非常關鍵。
大眾常常以為 AI 經濟的下一個轉折會來自模型能力,例如下一代 GPT、Gemini、Claude。模型能力當然重要,但如果你從價值流向看,另一個更底層的轉折是算力成本被重新定價。
如果自研晶片成功,可能發生兩件事。
第一,GPU 稀缺性下降,NVIDIA 的定價能力被壓縮。這不一定代表 NVIDIA 失敗,而是毛利池會被重新分配。
第二,推論成本下降,應用層的毛利才有機會改善。這對 OpenAI、Anthropic、Google Gemini、各種 AI agent、coding assistant、enterprise AI 都重要。因為只要推論成本仍然高,每一次使用都是成本事件;一旦推論成本大幅下降,應用層才更接近傳統軟體的經濟結構。
這就是為什麼 Apoorv 說,ASIC program 如果有 breakout success,可能會是該層最大的 repricing。它改變的不是單一硬體產品,而是整個 stack 的 bargaining power。
從這個角度看,AI 產業接下來幾年的重要新聞,不只在模型 benchmark。
也在晶片 road map、雲端 capex guidance、推論成本曲線、資料中心利用率,以及誰能把每個 token 的成本打下來。
訓練 vs 推論:AI 的成本曲線會不會換一個形狀
課中有學生問,是否只有 inference 變得比 training 更大,這個三角形才會翻轉。Apoorv 回答,這是 Nvidia 財報電話會議裡最受關注的資訊之一,也就是 Nvidia fleet 裡 inference 占比。他提到自己上次看到約 40% 用於 inference、60% 用於 training,並猜測 inference 占比會隨時間提高。
這段值得展開,因為 training 和 inference 的經濟性很不同。
訓練像一個大型工程專案。你知道什麼時候開跑,大概知道需要多少 GPU、跑多久,利用率可以很高。它是資本密集,但排程相對可控。
推論像服務業。人醒著的時候會問問題,工作時間會爆量,假日可能下降。Apoorv 還提到感恩節、聖誕節附近 workload 會下降。等 AI agents 真正接手更多任務,推論可能會變成 24/7,但也更難預測。
這對商業模式有直接影響。
如果需求主要是訓練,價值集中在少數 frontier labs 和大規模訓練集群。這對晶片供應商和雲端建設商很有利。
如果需求逐漸轉向推論,問題就會變成服務成本、延遲、峰值負載、快取、模型壓縮、專用晶片、使用者定價。這時候應用層和 infra 層都有機會重新切分價值,但前提是成本能被壓下來。
換句話說,AI 從「誰能訓練最大模型」走向「誰能最便宜、最穩定地服務最多任務」,經濟問題就會換一個戰場。
半導體為什麼最賺:不是因為它酷,而是因為市場集中
有學生問 profitability 在哪裡。Apoorv 直接回答:最賺的是 semis layer,而且差很多。他估計 data center revenues 的 margin 大約 75%,應用層 revenue 則可能在 0% 到 30% 之間,視你問誰而定。
這一段的重點不是精確數字,而是差距。
如果底層半導體可以有接近 75% 的毛利,而上層應用在 0% 到 30% 之間掙扎,那 AI 的利潤池就不是平均分布。它高度集中。投影片後面也寫著「But profits remain at the Semis layer」,並用 gross profit share 比較 AI 2024、AI 2026 與 Cloud Software。講者口述說,從 profitability 看,triangle 甚至更集中。
為什麼會這樣?
不是因為晶片比較神秘,而是因為供給端集中。當一層裡有少數玩家掌握關鍵資源,尤其在需求爆發而供給跟不上時,定價權就會很強。NVIDIA 在這堂課裡不斷被當成例子,不只是因為它有好產品,而是因為它站在一個需求爆發、供給稀缺、替代品尚未成熟的位置。
對創業者來說,這有一個不太浪漫的啟示:不是離使用者最近就最賺錢。
最賺錢的位置,往往是「大家都需要你,但短期內沒人能替代你」。
如果你想創晶片公司,先想清楚五個客戶裡誰會買
課堂裡有學生問,如果 Google、AWS、Meta 都做自己的 TPU 或 ASIC,晶片新創還有什麼空間?
Apoorv 的回答很直接:有約 3,000 億美元 revenue 可以爭,但其中大約一半來自大型 hyperscalers。也就是說,如果你今天創辦一家晶片公司,你的客戶群不是數百萬個消費者,也不是幾千家中小企業,而是極少數、訂單非常大的客戶。
這跟做 consumer app 或 enterprise software 完全不同。
做消費產品,你可以追求使用者增長、網路效應、留存。做企業軟體,你可以建立 sales motion、擴張 account、做 land and expand。做晶片,你必須面對幾個超大買家:他們懂技術,有自己的 road map,有議價能力,也可能自己做。
所以 Apoorv 給的判斷很簡單:如果你要創晶片公司,第一個問題應該是,你要先賣給那五家中的哪一家?
這句話把 deep tech 創業拉回現實。
技術突破不等於公司成立。公司成立不等於客戶願意買。客戶願意買不等於能 scale。尤其在 AI 晶片這種市場,產品、製造、供應鏈、軟體 stack、客戶驗證週期都很長。你不是把東西上架到 app store,而是要進入少數巨頭的基礎設施計畫。
這也是為什麼 AI 堆疊每一層的創業風險完全不同。應用層可能死於毛利;infra 層可能死於平台夾殺;晶片層可能死於客戶集中和週期錯配。
垂直整合會不會贏?Google、Apple、Meta 給的答案不完全一樣
有學生問,過去的科技週期是不是沒有完全垂直整合的玩家勝出。Apoorv 的回答是,網際網路 super cycle 最大贏家大概是 Google,而 Google 其實相當垂直整合。它有搜尋、有廣告、有使用者體驗,也有自己的底層系統。行動週期的大贏家是 Apple。社群的大贏家是 Meta。雲端則比較不一樣,沒有單一玩家完全贏,AWS、GCP、Azure 形成三大寡占。
這段討論很值得放到 AI 來看。
AI 的終局可能更偏向垂直整合,因為每一層都互相牽制。模型能力依賴算力,算力依賴晶片,晶片依賴資料中心與電力,應用體驗依賴模型成本與延遲,商業模式又依賴分發和使用者場景。只做其中一層,可能很難完全掌握命運。
這也是為什麼 NVIDIA 嘗試 DGX Cloud,Google 用 TPU 支撐 Gemini 和 GCP,Microsoft 把 OpenAI、Azure、Copilot 綁在一起,Meta 一邊做模型一邊做 MTIA。大家都知道,如果只站在一層,可能會被另一層掐住脖子。
但垂直整合也不是免費午餐。
它需要資本、人才、耐心、組織能力,以及跨層協調。Google 可以把 TPU、GCP、Gemini 拆成不同事業單位分析,不代表每家公司都能這樣做。對多數新創來說,垂直整合不是口號,而是成本爆炸。
所以更實際的問題不是「垂直整合好不好」,而是「你控制了哪個不可替代的瓶頸」。
沒有瓶頸,就沒有定價權。
2024 到 2026:AI revenue 成長五倍,但形狀幾乎沒變
課程後半段,Apoorv 回到一張標題很醒目的圖:「AI Revenue has grown 5x in 2y!」圖表比較 2024 Q1 和 2026 Q1,總量從約 900 億美元到約 4,350 億美元,分類包含 Apps、Infra、Semis。
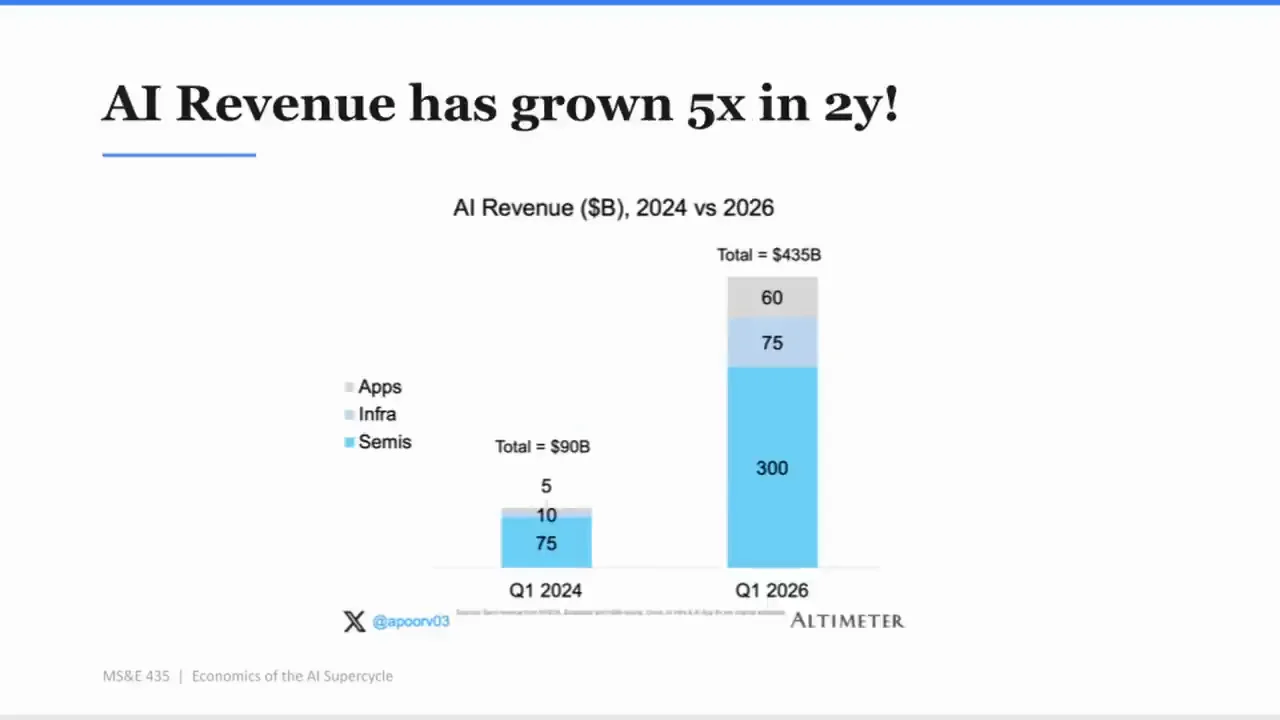
如果只看總量,這是非常漂亮的故事。
兩年五倍,代表需求不是幻覺。企業在買,消費者在用,雲端在建,晶片在賣。這種速度足以解釋為什麼所有人都把 AI 當成最大題材。
但 Apoorv 的觀察不是停在「五倍」。他更在意「形狀沒有變」。應用雖然成長超過十倍,但還沒有對整體結構造成夠大的改變。Semis 還是最大塊,且其中大部分是 NVIDIA。Apps 這一塊看似熱鬧,但實際上高度集中,約九成由兩家公司構成。Infra 則是戰火最猛烈、最不穩的區域。
這裡有三個層次。
第一,AI 確實在長大。
第二,長大的錢主要先流向底層。
第三,最終能不能變成 cloud software 那種上層厚、應用厚、利潤分布更成熟的形狀,還需要時間。
投影片「But profits remain at the Semis layer」把這個問題講得更清楚。收入成長很快,但 gross profit 仍留在 semis。這對投資人和創業者都是提醒:不要只看 TAM,也要看 gross profit pool。
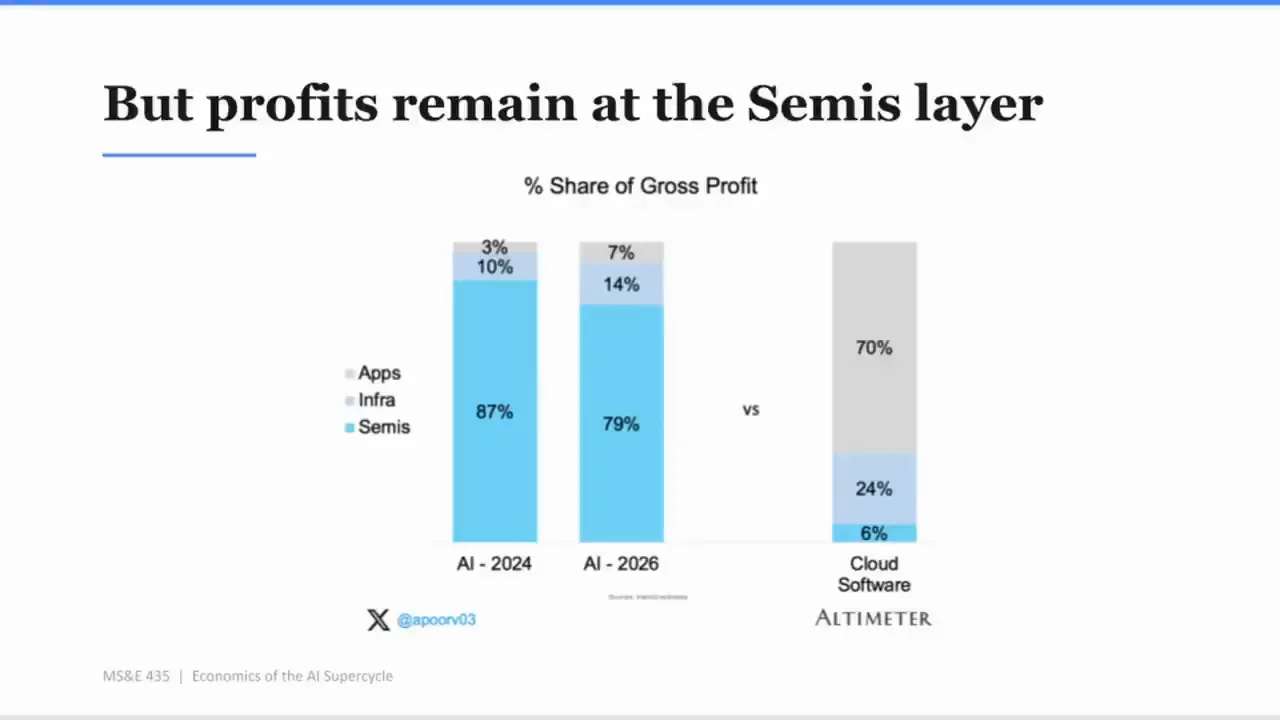
TAM 是故事。
毛利池才是現金。
消費 AI 的使用量很猛,但 95% 免費是一個很大的問號
後半段課程轉向 consumer AI。Apoorv 展示一張 AI Apps Weekly Active Users 圖,列出 ChatGPT、Gemini、DeepSeek、Character AI、Perplexity、Grok、Claude 等應用,來源是 SensorTower。他說,consumer AI 是 coding 之外目前最大的 AI 市場之一,ChatGPT 使用量非常高,但大多數是免費。
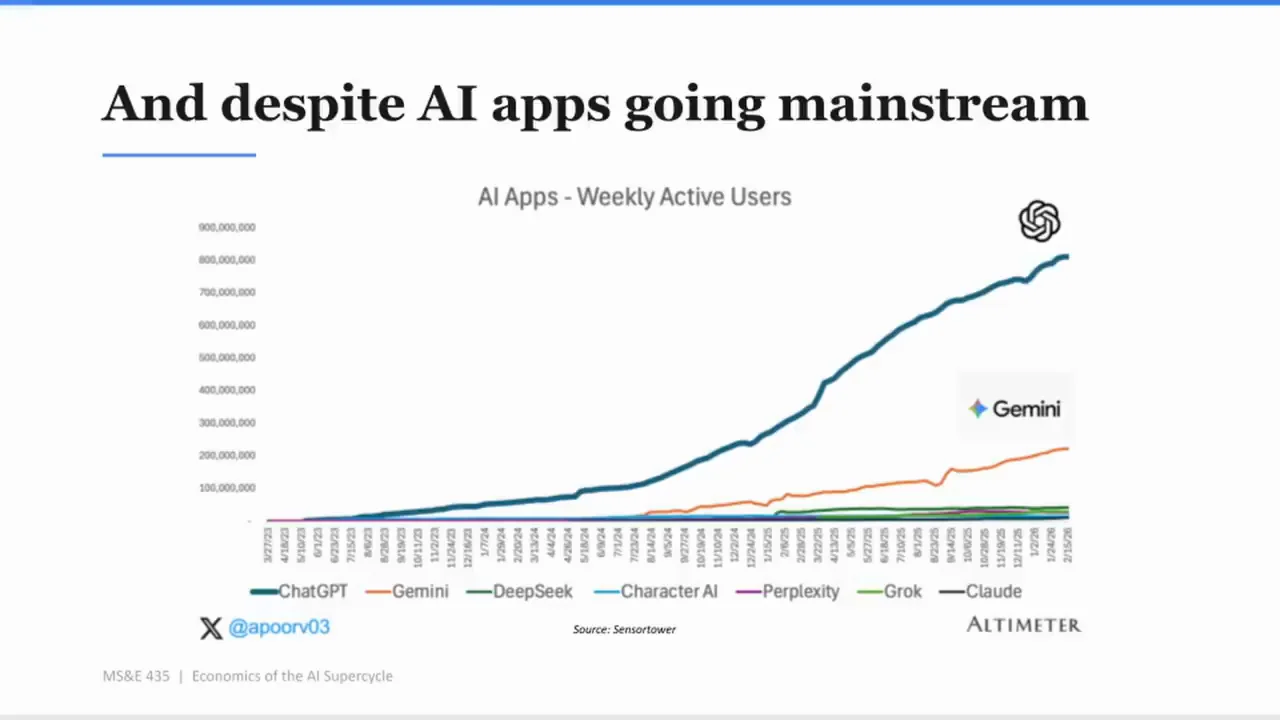
接著他補了一句很重的數字:約 95% 的使用者是 free。
這句話讓整個 consumer AI 故事變得更複雜。
使用量代表產品價值,但不代表商業模式已經成立。如果 95% 使用者不付費,而每一次使用又有推論成本,那麼免費使用不是傳統網路時代那種「先拿流量,廣告以後再來」那麼簡單。因為 AI 不是單純多送幾頁內容或多跑幾個 feed impression。它每一次互動都要消耗算力。
所以問題變成:AI consumer apps 最後靠什麼變現?
訂閱制是一條路。ChatGPT Plus、Pro、Team、Enterprise 都是這個方向。但訂閱制有天花板。不是每個人都會每月付費,尤其當免費版本已經夠好。
廣告是另一條路。但廣告放進 AI 對話裡,不像放進搜尋結果或社群 feed 那麼自然。當使用者和 AI 討論工作、學習、健康、公司策略、私人決策時,插入廣告會變得很敏感。Apoorv 用 Facebook IPO 的歷史做類比:當年很多人放空 Facebook,理由是廣告在桌機有效,但手機螢幕太小,沒有空間。後來市場找到了手機廣告的形式。現在 AI 也面臨類似問題:不是不能有廣告,而是還不知道好的廣告型態長什麼樣。
這裡的 alpha 不在於喊「AI 廣告會很大」。
真正的 alpha 在於理解,什麼樣的廣告不會破壞 AI 對話的信任。
ChatGPT 到底是 WhatsApp、Instagram,還是 Spotify?
為了判斷 consumer AI 的最終規模,Apoorv 拿非 AI 消費產品做類比。他展示 Consumer Apps Weekly Active Users,列出 YouTube、TikTok、Spotify、Chrome、Facebook、Amazon、Instagram、X 等產品,並把產品分成三類。
第一類是接近三十億使用者規模的 core utility,像 WhatsApp、Chrome。這些產品接近生活必需品,你很難不用。
第二類是 15 億到 20 億使用者規模的 social products,像 Instagram、TikTok、Facebook。它們不是生活必需品,但有強網路效應。朋友在上面,你就更可能在上面。
第三類是 mainstream 但比較 niche 的產品,例如 Amazon、Spotify、Twitter/X。你有特定需求時會去,但它不是每個人每天都必須用,也不一定有最強社交網路效應。
然後他問:ChatGPT 和 Gemini 比較接近哪一類?
投影片 Slide 34 把 Consumer 與 AI Apps 放在一起。口述裡,Apoorv 說 ChatGPT 剛剛超越 niche app category,Gemini 還沒有。ChatGPT 正往 social 的方向走,但他作為 OpenAI 投資人,會希望它往 core utility 走。
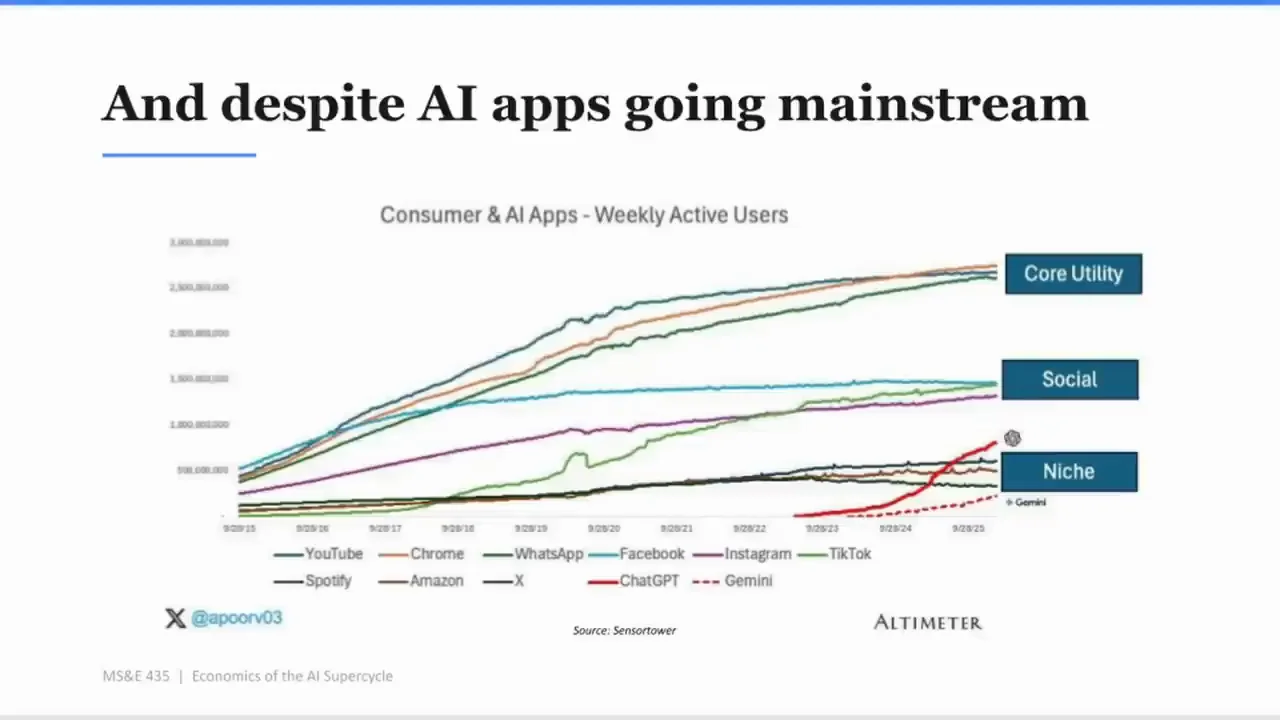
這是整篇演講後段最關鍵的 consumer AI 問題。
ChatGPT 如果只是 Spotify 或 X 等級的 niche utility,那它仍然可以是一家非常大的公司,但它不一定能支撐大家想像中的全部估值和算力投資。如果它能變成 WhatsApp、Chrome、YouTube 那種日常必需品,商業模式的空間就完全不同。
但要成為 core utility,它不能只是一個「偶爾問問題」的地方。Apoorv 提到,ChatGPT 目前不是你和別人傳訊息的地方,也不是你的 email inbox。這句話其實是在問產品入口:AI 應用要成為必需品,是否必須嵌入日常工作流,成為訊息、知識、文件、任務、搜尋、決策的中心?
如果答案是 yes,那 AI app 的競爭就不只是模型品質,而是 distribution、workflow、default behavior 和 trust。
這堂課真正教的,是一套判斷 AI 公司的問題清單
把整堂課串起來,它其實不是在給單一答案。它是在教一套問題清單。
如果你看一間 AI 應用公司,你要問:它的每個新增使用者是不是帶來新增推論成本?它的毛利會不會隨規模改善?它有沒有定價權?它是工作流裡的必需品,還是好玩的外掛?它靠訂閱、企業合約,還是未來某種廣告模型?
如果你看一間 AI infra 公司,你要問:它是功能還是平台?它解的問題會不會被雲端巨頭內建?它有沒有跨模型、跨雲、跨客戶的中立價值?它是短期補洞,還是長期控制面?
如果你看一間晶片或硬體公司,你要問:它要賣給誰?五個最大 hyperscalers 裡哪一家會買?它能不能進入供應鏈?它的軟體 stack 夠不夠成熟?它是 NVIDIA 的補充、替代,還是某個垂直 workload 的專用解?
如果你看一家大型平台公司,你要拆成事業單位:它的晶片在哪一層?雲在哪一層?模型在哪一層?應用在哪一層?哪一層是成本,哪一層是收入,哪一層是防禦,哪一層是利潤?
這些問題比「AI 會不會改變世界」更實用。
因為 AI 很可能會改變世界,但世界不會自動把利潤分給每一家公司。
結尾:這不是一堂 AI 熱潮課,是一堂 AI 成本課
第一堂課最後,投影片回到 schedule and speakers。Apoorv 說,後面九週會深入不同題目:GPU economy、gigawatt scale AI factories、enterprise AI、frontier lab、agent monetization、coding AI、life sciences。這些主題看起來分散,其實都圍繞同一個主問題。
AI 的價值最後會落在哪裡?
第一堂課給出的暫時答案,是一張尚未翻轉的三角形。底層很厚,半導體很賺,基礎設施競爭激烈,應用使用量很高但變現仍未完全證明。AI revenue 兩年成長五倍,但 profit pool 仍留在 semis。ChatGPT 已經越過 niche app 的門檻,但還沒證明自己是 WhatsApp/Chrome 等級的 core utility。廣告可能是大 unlock,但它必須被重新發明。ASIC 和推論成本可能改變整個 stack,但時間點不確定。
所以這堂課最好的地方,不是它告訴你買哪家公司。
它提醒你,別只看 demo。
看毛利。
別只看使用者數。
看付費率和成本。
別只看模型能力。
看推論成本、capex cycle、雲端議價權、晶片替代性。
真正的 AI 超級循環,不是每個人都突然變成軟體公司。
它更像一場新的工業化:有人蓋電廠,有人賣鏟子,有人鋪鐵路,有人做車站,有人開商店,有人最後成為城市入口。
如果你只看最熱鬧的街景,可能會以為錢都在店面。
但第一階段,收租的人可能在地下室。
這就是 Apoorv Agrawal 第一堂課想讓學生看見的事:AI 會很大,但大不等於好賺。真正的問題從來不是「AI 有沒有未來」。
真正的問題是:
你站在未來的哪一層?
查核說明
- 本文依據 Class #1 的課堂紀錄改寫,主軸保留原課堂順序:課程介紹、AI 價值三角形、軟體邊際成本差異、AWS/雲端類比、ASIC/TPU/MTIA、訓練與推論、半導體毛利、垂直整合、2024-2026 revenue/gross profit 圖、consumer AI 變現與廣告模型。
- 文中數字如 AI revenue 5x、2024/2026 revenue pool、75% 新增收入流向 semis、應用層毛利 0-30%、95% free users、ChatGPT/Gemini 與 consumer apps 週活比較,均來自課堂內容;其中部分為講者估算或課堂圖表估算,不視為 audited industry total。
- quiz、現場重複句與口誤已刪減;但保留了它們在課堂中服務的功能:用公司題目帶出 AI stack、speaker schedule 與後續九週議題。
- 本文有評論性延伸,例如「替別人墊算力成本」「下一季 release note 裡的一個小功能」「第一階段收租的人可能在地下室」,用於說明講者邏輯,不是逐字引用。
資料來源
- MS&E435 Class #1 本地課堂紀錄。
本頁由影片逐字稿、截圖與 AI 整理生成,內容可能需要回到原始來源查證。